Disease Prediction By Machine Learning Over Big Data From Healthcare Communities
چکیده پیش بینی بیماری توسط دستگاه یادگیری بر کلان داده ها از انجمن های بهداشتی مراقبتی: با پیشرفت وسیع اطلاعات در حوزه های Healthcare و بهداشت و درمان، تجزیه و تحلیل دقیق پزشکی منجر به پیشگیری از بیماری، مراقبت از بیمار و خدمات اجتماعی می شود. با این حال، دقت تجزیه و تحلیل هنگامی که کیفیت داده های پزشکی ناقص است، کاهش می یابد. در این مقاله، الگوریتم های یادگیری ماشین برای پیش بینی موثر شیوع مزمن در سیستم پیاده سازی و بررسی شده اند. همچنین مدل های پیش بینی بر روی داده های واقعی جمع آوری شده از بیمارستان های مرکزی چین در سال ۲۰۱۳ تا ۲۰۱۵، آزمایش شده است.
در مواردی که داده های ناقص وجود داشته، نویسندگان مقاله از یک مدل جهت بازسازی داده ها استفاده نموده اند. آزمایش های انجام شده در یک بیماری مزمن منطقه ای مغزی صورت گرفته است. همچنین یک شبکه عصبی نوین مبتنی بر کانولوشن ارائه شده که از داده های ساختاری و غیرساختاری دریافتی از بیمارستان ها استفاده می نماید. در مقایسه با چندین الگوریتم پیش بینی پیش بینی شده، دقت پیش بینی الگوریتم پیشنهادی نویسندگان این مقاله ۸/۹۴٪ است که سریعتر از الگوریتم پیش بینی ریسک بیماری یکپارچه مبتنی بر CNN است.
کلمات کلیدی : Big data analytics, machine learning, healthcare.
مقدمه:
بر اساس گزارش McKinsey ، ۵۰ درصد از آمریکایی ها مبتلا به یک یا چند بیماری مزمن هستند و ۸۰٪ از آمریکایی ها بابت مراقبت های پزشکی برای درمان بیماری مزمن هزینه می کنند. با بهبود استانداردهای زندگی، شیوع مزمن بیماری در حال افزایش است به طوری که در ایالات متحده، به طور میانگین ۲٫۷ تریلیون دلار در سال جهت درمان بیماری مزمن صرف می شود.
این مقدار معادل ۱۸ درصد کل تولید ناخالص ملی سالانه در آن کشور را تشکیل می دهد. مشکل بهداشتی بیماری های مزمن همچنین در بسیاری از کشورهای دیگر بسیار از مسایل مهم روز به شمار می رود. در کشور چین، بیماری های مزمن علت اصلی مرگ می باشد. در مورد تغذیه و بیماری های مزمن در سال ۲۰۱۵ نیز این مساله که ۸۶٫۶٪ از مرگ و میر را بیماری های مزمن تشکیل می دهد، قابل توجه است. از این رو، ارزیابی ریسک های مزمن سهولت با عنایت به افزایش داده های پزشکی موجود می بایست برنامه ریزی شود. همچنین جمع آوری داده های الکترونیکی پرونده های سلامت تریرون (EHR) به طور قابل توجهی راحت تر شده است. علاوه بر این، یک راهکار با کیفیت بالا با استفاده از پارادایم telematics ارائه شده است، به طوری که جمع آوری Big Data در زمان واقعی با موضوع سلامت کاربران تلفن همراه با استفاده از شبکه های پیشرفته وسایل نقلیه امکان پذیر شده است.
چن و همکاران در مقالات یک سیستم مراقبت بهداشتی را با استفاده از لباس هوشمند برای نظارت پایدار سلامت افراد پیشنهاد کرده اند. کیو و همکاران در مقاله به طور کامل سیستم های ناهمگن را مورد مطالعه قرار داده و بهترین نتایج را برای کمینه کردن هزینه درخت ها و موارد مسیر ساده برای سیستم های ناهمگن به دست آورده است. اطلاعات آماری بیمار، نتایج آزمایشات و تاریخ بیماری در EHR ثبت می شود، که این قابلیت را در اختیار می گذارد تا راه حل های بالقوه محدوده داده ها برای کاهش هزینه های مطالعات موردی پزشکی شناسایی شود. وانگ و همکاران در مقاله یک الگوریتم تخمین جریان را برای سیستم تلفنی پزشکی (Telehealth) همراه پیشنهاد کرده و یک پروتکل هماهنگی داده برای سیستم توزیع مبتنی بر PHR(پرونده پزشکی شخصی) طراحی کرده است. بیتس و همکاران در مقاله شش برنامه کاربردی از کلان داده ها را در زمینه مراقبت های بهداشتی ارائه می دهد. کیو و همکاران در مقاله یک الگوریتم به اشتراک گذاری داده بهینه بزرگ را پیشنهاد داده است تا اطلاعات پیچیده ای را که در تلفن های همراه با تکنیک های ابری (Cloud) ارائه می شود، مدیریت نماید. یکی از برنامه های کاربردی، شناسایی بیماران پر خطر است که می توانند برای کاهش هزینه های پزشکی استفاده کنند زیرا بیماران پر خطر اغلب نیاز به مراقبت های بهداشتی گران تری نسبت به بیماران عادی دارند. علاوه بر این، در اولین مقاله ارائه شده در سیستم فیزیکی سایبری بهداشت و درمان، ارزیابی ریسک سلامت با توجه به ابتکار در پیاده سازی برنامه های مراقبت سلامت تعریفی جدید پیدا کرده است. پیش بینی با استفاده از مدل های خطر سنتی بیماری، معمولاً شامل الگوریتم یادگیری ماشین (به عنوان مثال، رگرسیون لجستیک و تجزیه و تحلیل رگرسیون و غیره) و به ویژه یک الگوریتم یادگیری تحت نظارت با استفاده از داده های آموزشی با برچسب برای آموزش مدل، می شود.

در مجموعه آزمون، بیماران را می توان به دو گروه با خطر بالا و یا خطر کم طبقه بندی کرد. این مدل ها در شرایط بالینی ارزشمند هستند و به طور گسترده مورد مطالعه قرار می گیرند. با این حال، این طرح ها دارای مشخصات و نقص های زیر است. مجموعه داده ها معمولاً برای بیماران و بیماری هایی با شرایط خاص کم می باشد، البته جهت تهیه ویژگی ها از طریق تجربه اقدام می شوند؛ با این حال، این ویژگی های از پیش انتخاب شده، ممکن است تغییرات در بیماری و عوامل موثر بر آن را برآورده نکنند. با توسعه تکنولوژی تحلیل کلان داده ها، توجه بیشتر به پیش بینی بیماری از منظر تحلیل Big Data مورد توجه قرار گرفته است، بنابراین تحقیقات مختلف با انتخاب ویژگی ها به طور خودکار از تعداد زیادی از داده ها برای بهبود دقت طبقه بندی ریسک انجام شده است. با این حال، در این بخش برای بهبود وضعیت اطلاعات ساختاری را در نظر می گیرند. برای داده های بدون ساختار، به عنوان مثال، با استفاده از شبکه عصبی کانولوشن (CNN) برای استخراج ویژگی های متن به طور خودکار که توجه زیادی را به خود جلب کرده و از قضا نتایج بسیار خوبی را هم به دست آورده است . علاوه بر این، بین بیماری ها در مناطق مختلف تفاوت زیادی وجود دارد که در درجه اول به دلیل عواقب گوناگون آب و هوا و زندگی در منطقه است.
برای حل این مشکلات، نویسندگان مقاله، داده های ساختاری و غیر ساختاری در زمینه مراقبت های بهداشتی را برای ارزیابی خطر بیماری ترکیب کرده اند. ابتدا ایشان از مدل فاکتور پنهان برای بازسازی داده های از دست رفته پرونده های پزشکی که از یک بیمارستان در مرکز چین گرفته شده استفاده کرده اند. دوم، با استفاده از دانش آماری، عمده بیماری های مزمن در منطقه را تعیین نموده اند. سوم، برای مدیریت داده های ساختاری، از مشورت با متخصصین بیمارستان استفاده کرده اند تا ویژگی های مفید را استخراج کنند. برای داده های متنی بدون ساختار، ویژگی ها را به طور خودکار با استفاده از الگوریتم CNN انتخاب می کنند. در نهایت، نویسندگان مقاله، پیشنهاد جدیدی برای پیش بینی ریسک بیماری های چندجمله ای مبتنی بر شبکه های عصبی کانولوشن یا CNN که به نام (CNN-MDRP) بیان کرده اند، برای داده های ساخت یافته و غیر ساختاری ارائه می دهند که مدل ریسک بیماری با ترکیبی از ویژگی های ساختاری و غیر ساختاری بدست می آید. همچنین در نهایت از طریق آزمایش، این نتیجه را اعلام نموده اند که عملکرد CNN-MDPR بهتر از سایر روش های موجود است.
بنابراین در بررسی طبقه بندی خطر بر اساس تجزیه و تحلیل کلان داده ها، چالش های زیر باقی می ماند: چگونه داده های گم شده باید مورد توجه قرار گیرد؟ چگونه باید بیماری های مزمن اصلی در یک منطقه مشخص و ویژگی های اصلی بیماری در منطقه تعیین شود؟ چگونه می توان تکنولوژی تجزیه و تحلیل داده های بزرگ را برای تجزیه و تحلیل بیماری و ایجاد یک مدل بهتر استفاده کرد؟
باقی مانده از این گزارش مقاله به شرح زیر است. مجموعه داده ها و مدل ها را در قسمت دوم توصیف می شود. روش های مورد استفاده در این مقاله در بخش سوم شرح داده شده است. عملکرد الگوریتم های CNN-UDRP و CNN-MDRP در بخش چهارم مورد بحث قرار گرفته است. در ادامه نیز نتایج کلی را در بخش پنجم ارائه می شود. در نهایت بخش ششم این مقاله، در مورد نتیجه گیری می باشد.
۲٫دیتاست و توصیف مدل:
در این بخش، نویسندگان مقاله، مجموعه داده های بیمارستانی را در این مطالعه توصیف می کنند. علاوه بر این، مدل پیش بینی خطر و روش های ارزیابی را ارائه می دهند.
الف) داده های بیمارستانی:
مجموعه داده های بیمارستان مورد استفاده در این مطالعه شامل اطلاعات بیمارستان های واقعی است و داده ها در مرکز داده ذخیره می شوند. برای محافظت از حریم خصوصی و امنیت بیمار، یک مکانیزم دسترسی به امنیت ایجاد شده و داده های ارائه شده توسط بیمارستان عبارتند ازEHR، داده های تصویر پزشکی و داده های ژنی که از سال ۲۰۱۳ تا ۲۰۱۵ از این مجموعه داده های سه ساله استفاده شده است. داده های این مقاله بر روی اطلاعات مربوط به بخش های بیمارستان مربوط می شود که شامل ۳۱٫۹۱۹ بیمار بستری با پرونده های ۲۰٫۳۲۰٫۸۴۸ است. داده های بخش بیمارستان عمدتاً متشکل از داده های متنی ساختار یافته و بدون ساختار است. داده های ساختاری شامل داده های آزمایشگاهی و اطلاعات پایه بیمار مانند سن بیمار، عادات جنسیتی و زندگی و غیره است. در حالی که داده های متنی بدون ساختار شامل روایت بیمار از بیماری او، پرونده های بازجویی و تشخیص پزشک و غیره است. همانطور در جدول ۱ که نشان داده شده است، اطلاعات بیمارستانی در زندگی واقعی از مرکز چین به دو دسته تقسیم می شوند، یعنی داده های ساخت یافته و داده های متنی بدون ساختار.
همانطور که در جدول ۲ نشان داده شده است، برای ارزیابی بیماری اصلی که بر این منطقه تأثیر می گذارد، آمار سالانه تعداد بیماران، نسبت جنس بیماران و بیماری های عمده در این منطقه را از داده های متنی ساختار یافته و غیر ساختاری، آمارهای آماری ارائه می شود. از جدول ۲ مشخص است که نسبت بیماران مرد و زن بستری در بیمارستان هر سال تفاوت کمی دارد و بیشتر بیماران در سال ۲۰۱۴ در بیمارستان بستری شده اند. علاوه بر این، بستری شدن به علت بیماری های مزمن، بخش بزرگی از این منطقه آمار از داده ها را به خود اختصاص داده است. برای مثال، بیماران بستری شده با بیماری های مزمن سینه، فشار خون بالا و دیابت ۶۳/۵٪ از کل بیماران در سال ۲۰۱۵ به بیمارستان هستند، در حالیکه سایر بیماری ها نسبت کمی دارند. در این مقاله،عمدتاً بر پیش بینی خطر سکته مغزی تمرکز شده است زیرا سکته مغزی یک بیماری کشنده به شمار می رود.

ب) پیش بینی ریسک بیماری:
از جدول ۲، بیماری اصلی مزمن در این منطقه به دست می آید. هدف از این مطالعه، پیش بینی این است که آیا بیمار در میان جمعیت بالقوه مبتلا به سکته مغزی با توجه به تاریخ پزشکی خود است یا خیر. به عبارت دیگر، در نظر بگیرید مدل پیش بینی خطر برای سکته بزرگ مغزی به عنوان روش یادگیری نظارت شده در یادگیری ماشین، یعنی مقدار ورودی ارزش مشخصی بیمار است. X=(x_1,x_2,…,x_n) که شامل اطلاعات شخصی بیمار مانند سن ، جنسیت، شیوع علائم و عادات زندگی (سیگار کشیدن یا نه) و سایر داده های ساخت یافته و داده های بدون ساختار می باشد.
مقدار خروجی C است، که نشان می دهد که آیا بیمار در میان جمعیت با خطر بالای سکته مغزی است. C={C_0,C_1} جایی که C_0نشان دهنده بیمار در معرض خطر سکته مغزی است و C_1 بیانگر عدم امکان خطر ابتلا به سکته مغزی می باشد. زیر مجموعه داده ها، تنظیمات آزمایشی، ویژگی های داده ها و یادگیری الگوریتم ها به طور خلاصه برای مجموعه داده ها، با توجه به ویژگی های مختلف بیمار و بحث با پزشکان به شرح زیر می باشد:
داده های ساخت یافته(S-data): از اطلاعات ساختار یافته بیمار برای پیش بینی اینکه بیمار در خطر ابتلا به سکته مغزی استفاده شده است.
داده های متنی (T-data): از متن بدون ساختار، برای پیش بینی اینکه آیا بیمار در معرض خطر سکته مغزی است یا خیر، استفاده شده است.
داده های ساخت یافته و متن (S & T data) : از داده S-data و T-data بالا استفاده می شود تا داده های ساخت یافته و داده های متنی بدون ساختار را برای پیش بینی اینکه آیا بیمار در معرض خطر ابتلا به سکته بزرگ مغزی قرار دارد یا خیر. از تنظیمات آزمایش و ویژگی های داده ها، تعداد ۷۰۶ بیمار را به عنوان داده های آزمایش انتخاب شده و به طور تصادفی داده ها را به داده های آموزشی و داده های آزمایش تقسیم می شوند. نسبت مجموعه آموزش و مجموعه آزمون ۶ به ۱ انتخاب شده است، یعنی ۶۰۶ بیمار به عنوان داده های آموزش تنظیم شده در حالی که ۱۰۰ بیمار به عنوان مجموعه داده های آزمون در نظر گرفته شده است. زبان C++ به عنوان زبان پیاده سازی برای یادگیری ماشین و الگوریتم های یادگیری عمیق استفاده شده و با استفاده از مراکز داده به صورت موازی مراحل اجرایی انجام گرفته است. در این مقاله، برای S-data، با توجه به مشورت صورت گرفته با پزشکان و تجزیه و تحلیل همبستگی پیرسون، ویژگی های جمعیت شناسی بیمار و برخی از ویژگی های مرتبط با سکته های مغزی و عادات زندگی (مانند سیگار کشیدن) را استخراج می نمایند. سپس تعداد ۷۹ ویژگی بیمار را به دست می آورند. برایT-data، ابتدا ۸۱۵٫۰۷۳ کلمه را در متن برای یادگیری بستن کلمه استخراج نموده اند. سپس از قابلیت استخراج مستقل توسط CNN استفاده می کنند. در ادامه نویسندگان مقاله، الگوریتم های یادگیری ماشین و یادگیری عمیق مورد استفاده در این کار را به طور خلاصه معرفی نموده اند. برای داده S، برای پیش بینی خطر ابتلا به سکته مغزی از سه الگوریتم یادگیری ماشین متعارف استفاده کرده اند، به عنوان مثال، Naïve Bayes (NB)، K نزدیکترین همسایگی (KNN)، و تصمیم الگوریتم درخت (DT) یا Decision Tree برای T-data، پیشنهاد شده است تا الگوریتم پیش بینی خطر ابتلا به بیماری Unimodal مبتنی بر CNN (CNN-UDRP) را برای پیش بینی خطر ابتلا به سکته مغزی استفاده گردد.
در بقیه مقاله،CNN-UDRP (T-data) الگوریتم CNN-UDRP را برای T-data نشان می دهد. برای اطلاعاتS & T، خطر ابتلا به سکته مغزی را با استفاده از الگوریتم CNN-MDRP پیش بینی می شود که به خاطر سادگی با CNN-MDRP (S & T-data) مشخص می شود. در بخش بعد، اطلاعات مربوط به CNN-UDRP (T-data) و CNN-MDRP اطلاعات (S & T) ارائه خواهد شد.
ج) روش های تخمین:
نویسندگان این مقاله، برای ارزیابی عملکرد در آزمایش اول، TP، FP، TN و FN را با توجه به تعاریف استاندارد آن ها در طول ارائه گزارشات در مقاله در نظر گرفته اند.

جایی که اندازه گیری F1 معیار هارمونیک وزنی دقیق و فراخوانی است و نشان دهنده عملکرد کلی است. علاوه بر معیارهای ارزیابی فوق، از منحنی عامل گیرنده (ROC) و ناحیه تحت منحنی (AUC) برای ارزیابی مزایا و معایب Classifier استفاده می کنند. همان طور که می دانید منحنی ROC نشان می دهد که رابطه بین نرخ واقعی مثبت (TPR) و نرخ مثبت کاذب (FPR)به چه صورت است. همچنین TPR و FPR به شرح زیر تعریف شده است:
![]()
در اطلاعات پزشکی، بیشتر به Recall به جای Precision توجه می کنیک. زیرا هرچه میزان Recall بالاتر باشد، احتمال بیمارانی که خطر ابتلا به بیماری را دارند، کمتر است.

۳٫ روش ها:
در این بخش، داده های محاسبه، الگوریتم پیش بینی ریسک بیماری های غیرمعمول مبتنی بر CNN که مخفف آن به صورت (CNN-UDRP)می باشد و الگوریتم پیش بینی خطر بیماری Unimodal (CNN-MDRP) مبتنی بر CNN که توسط نویسندگان این مقاله ارائه شده است را معرفی می نماییم.
الف ) داده های محاسبه:
برای داده های معاینه بیمار، تعداد زیادی از داده های از دست رفته به علت خطای انسانی وجود دارد. بنابراین، باید داده های ساخت یافته را پر می کردند. قبل از محاسبه داده ها، ابتدا اطلاعات پزشکی نامشخص یا ناقص را شناسایی کرده و سپس آنها را برای بهبود کیفیت داده اصلاح یا حذف کرده اند. سپس، از ادغام داده ها برای پیش پردازش داده استفاده می کنند. همچنین داده های پزشکی را برای تضمین تجزیه ناپذیری داده ها ادغام کرده اند. به عنوان مثال، قد و وزن را برای بدست آوردن شاخص توده بدن (BMI) یکپارچه شده در نظر گرفته اند. برای محاسبه داده ها، از مدل فاکتور پنهان استفاده می شده که برای توضیح متغیرهای قابل مشاهده از نظر متغیرهای پنهان ارائه شده است. بر این اساس فرض شده است که R_(M*N) ماتریس داده در مدل مراقبت بهداشتی است. تعیین ردیف، m نشان دهنده تعداد کل بیماران و تعیین ستون، n نشان دهنده تعداد ویژگی های ویژگی های هر بیمار است. فرض می شود که عوامل ناپایدار k وجود دارد، ماتریس اصلی R را می توان به صورت تقریبی تقسیم کرد:
![]()
بنابراین، هر Element Value را می توان به عنوان (r_uv ) ̂=P_u^T q_v در نظر گرفت، جایی که p_u بردار عامل کاربر است، که نشان دهنده اولویت بیمار به این عوامل بالقوه است، و q_v بردار عامل ویژگی ویژگی است. مقادیر p_u و q_v در فرمول بالا ناشناخته بوده و برای حل این مشکل می توان این مشکل را به یک مشکل بهینه سازی تبدیل کرد:
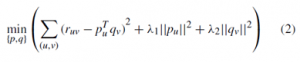
پارامترهایی که باید حل شوند، r_uv داده واقعی است و p_u وq_v پارامترهایی هستند که باید حل شوند و λ ثابت است که می تواند مانع از اضافه شدن در فرایند عمل شود. همچنین این امکان وجود دارد که با استفاده از روش stochastic gradient descent حل شود. معادله e_uv=(r_uv ) ̂- r_uv از طریق مشتق شده در بالا از مشکل بهینه سازی، نشان داده شده در الگوریتم ۱، که می تواند اطلاعات از دست رفته را دریافت کند.
CNN-BASED UNIMODAL DISEASE RISK PREDICTION
(CNN-UDRP (ALGORITHM
برای پردازش داده های متنی پزشکی، از الگوریتم پیش بینی خطر بیماری Unimodal مبتنی بر CNN که همان (CNN-UDRP) می باشد استفاده می گردد که می تواند به پنج مرحله زیر تقسیم شود.
الف) بازنمایی داده های متنی:
برای هر کلمه در متن پزشکی، از نمایش توزیع کلمه تعبیه کردن در پردازش زبان طبیعی استفاده می شود، یعنی متن به صورت بردار نمایش داده می شود. در این آزمایش هر کلمه به صورت یک نشان داده می شود.

ب) لایه کانولوشن از متن CNN:
هر دفعه کلمه S انتخاب می شود، جایی که S=5 در شکل ۱(b) است. به عبارت دیگر، دو کلمه از جلو و عقب هر بردار (t_i ) ́ را در متن انتخاب می شود، به عنوان مثال از ردیف به عنوان نمایه استفاده می کنیم که شامل یک ردیف ۵۰*۵=۲۵۰ است، یعنی (s_i=( (t_(i-2) ) ́,(t_(i-1) ) ́,(t_i ) ́,(t_(i+1) ) ́,(t_(i+2) ) ́)) ́همانطور که در شکل ۱ (b) نشان داده شده است، برای s1، s2، sn1 وsn، یک بردار صفر برای پر کردن اتخاذ می شود. ماتریس وزن انتخابی W^1∈R^(100*250) همانطور که در شکل ۱ (a) نشان داده شده است، یعنی وزن ماتریس W^1 شامل ۱۰۰ فیلتر کانواولو و اندازه هر فیلتر ۲۵۰ است. انجام عملیات کانولوشن در W^1 ، برابر باs_i می باشد که مقدار i از ۱ تا n خواهد بود. همانطور که در شکل ۱ (c) نشان داده شده است. روند محاسبات به این شکل است:
![]()
جایی که I , j از ۱ تا n خواهد بود و W^1 [i] ماتریس i ام از وزن ها می باشد. همچنین “.” بیانگر ضرب نقطه ای است. b^1∈R^100 یک اصطلاح Bias است و f(.) یک تابع فعال است (در این آزمایش از تابع tanh به عنوان تابع فعال سازی استفاده می شود). بنابراین امکان وجود دارد که یک نمودار ویژگی ۱۰۰ * n داشته باشیم:
![]()
ج) لایه Pool از CNN:
با در نظر گرفتن خروجی لایه کانوالو به عنوان ورودی لایه جمع کننده،از عملیات (max-pooling pooling) استفاده می شود همانطور که در شکل ۱ (d) نشان داده شده است، یعنی حداکثر مقدار n عناصر هر ردیف در ویژگی را انتخاب می کند ماتریس گراف:
![]()
پس از جمع آوری حداکثر، ویژگی های ۱۰۰ * ۱ برای h^2 را به دست می آورند. دلیل انتخاب عملیات جمع کردن حداکثر این است که نقش هر کلمه در متن به طور کامل برابر نیست، با حداکثر جمع کردن این امکان وجود دارد تا عناصری که نقش کلیدی در متن بازی می کنند انتخاب شود. به رغم طول های مختلف نمونه های مجموعه آموزش ورودی، متن به یک بردار طول ثابت تبدیل می شود پس از لایه کانوالو و لایه Pooling، به عنوان مثال، در این آزمایش، پس از convolution و pooling، ۱۰۰ ویژگی از متن را دریافت می شود.
د) ارتباط کامل لایه های متنی CNN
لایه Pooling با یک شبکه عصبی به طور کامل متصل شده است که همانطور که در شکل ۱ (E) نشان داده شده است، پردازش محاسباتی خاص این است که:
![]()
جایی که h3 مقدار لایه اتصال کامل است، w^3و h^3وزن و انحراف مربوطه است.
ه) طبقه بندی CNN
لایه اتصال کامل به طبقه بندی پیوند داده می شود، برای طبقه بندی، یک classmax را انتخاب می شود، همانطور که در شکل ۱ (f) نشان داده شده است.
CNN-BASED MULTIMODAL DISEASE RISK PREDICTION
(CNN-MDRP (ALGORITHM
از آنچه که در بالا بحث شده است می توانیم اطلاعاتی را دریافت کنیم که CNN-UDRP تنها از داده های متن برای پیش بینی اینکه آیا بیمار در معرض خطر سکته مغزی است استفاده می کند.
همانطور که در شکل ۱ نشان داده شده است، به این نتیجه می رسیم که برای داده های متنی ساختار یافته و بدون ساختار، الگوریتم CNN-MDRP را بر اساس CNN-UDRP طراحی شده است. همانطور که در شکل ۱ (ad) نشان داده شده است، پردازش داده های متنی با CNN-UDRP مشابه است و می تواند ۱۰۰ ویژگی در مورد مجموعه داده های متن را استخراج کند. برای ساختار داده ها، می بایست ۷۹ ویژگی استخراج شود. همانطور که در شکل ۱ (g) نشان داده شده است سپس، با استفاده از ۷۹ ویژگی در داده S و ۱۰۰ ویژگی در T-data، با استفاده از یکپارچگی سطح ویژگی انجام می شود. لازم به ذکر است برای لایه اتصال کامل، روش های محاسباتی با الگوریتم CNN-UDRP مشابه هستند. از آنجا که تغییر تعداد ویژگی ها، ماتریس وزن مربوطه و تعویض به w_new^3 و b_new^3 جدید تغییر می کند. همچنین از طبقه بندی softmax استفاده می کنیم. در ادامه نیز طبق آنچه که در مقاله آورده شده است،ا نحوه آموزش الگوریتم CNN-MDRP را معرفی خواهیم کرد، فرایند آموزش ویژه به دو قسمت تقسیم می شود:
۱٫ آموزش WORD EMBEDDING
برداری که برای آموزش کلمات، در نظر گرفته شده است نیازمند اطلاعات اولیه خام می باشد که تغییراتی روی آن اعمال نشده باشد. در این مقاله، اطلاعات متن تمام بیماران در بیمارستان از مراکز داده پزشکی استخراج شده است. پس از Data Cleaning روی داده ها، آنها را به صورت مجموعه ای تنظیم می شوند. با استفاده از ابزار تقسیم بندی کلمه ICTACLAS، ابزار word2vec ابزار الگوریتم n-skip gram، بردار کلمه را آموزش می دهد، بعد بردار کلمه به ۵۰ تنظیم می شود، پس از آموزش حدود ۵۲٫۱۰۰ کلمه در بردار کلمه گرفته می شود.
۲٫ پارامترهای آموزش CNN-MDRP
در الگوریتم CNN-MDRP، پارامترهای آموزشی خاص w^3 و b^3 است w_new^3 و b_new^3 از روش شبیه سازی تصادفی برای آموزش پارامترها استفاده می شود و در نهایت به ارزیابی ریسک بیماران مبتلا به سکته مغزی می توان رسید. برخی از ویژگی های پیشرفته در مطالعات آینده مورد آزمایش قرار می گیرند، مانند ابعاد فراکتال، تبدیل موجک دوتایی و غیره.
۴٫ نتایج:
در این بخش، در مورد عملکرد الگوریتم های CNN-UDRP و CNN-MDRP از چندین جنبه، یعنی زمان اجرای، Sliding Window، تکرار و ویژگی متن، بحث شده است.
الف ) بررسی زمان اجرای الگوریتم :
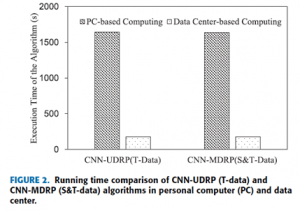
زمان اجرای (CNN-UDRP (T-data و الگوریتم های (CNN-MDRP (S & T-data را در رایانه شخصی (پردازنده دو هسته ای، RAM 8.00G) و مرکز داده (۶ عدد پردازنده با مشخصات core * 2 * 7D84core، ۴۸ * ۷D336G RAM) مقایسه شده است. در اینجا، یک تکرار CNN مشابه ۱۰۰ را ایجاد و ۱۰۰ عنصر متنی را استخراج شده است. همانطور که در شکل ۲ نشان داده شده است، برای الگوریتم (CNN-UDRP (T-data زمان اجرا در مرکز داده ۱۷۸٫۵ است در حالی که زمان در کامپیوتر شخصی ۱۶۴۶٫۴ است. الگوریتم (CNN-MDRP (S & T-data زمان اجرای آن در مرکز داده ۱۷۸٫۲ ثانیه است در حالیکه زمان در رایانه شخصی ۱۶۳۷٫۲ ثانیه است. به عبارت دیگر، سرعت در حال اجرا از مرکز داده ۹٫۱۸ برابر در رایانه شخصی است. علاوه بر این، ما می توانیم زمان اجرای الگوریتم ارائه شده (CNN-UDRP (T-data و (CNN-MDRP (S & T-data را در نظر گرفته که اساسا از رقم مشابه است، به طوری که اگر بعد از چندین ویژگی (CNN-MDRP (S & T اضافه کردن داده های ساختاری، در زمان تغییر قابل توجهی نمی کند. آزمایش های بعدی بر اساس نتایج در حال اجرا مرکز داده است.
ب) بررسی اثر Sliding Window جهت شمارش کلمات:
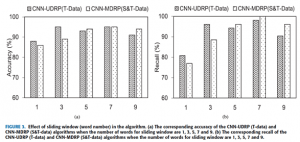
هنگام استفاده از کانولوشن CNN، می بایست ابتدا تعداد کلمات برای لغزاندن windofirst تایید شود. در این آزمایش، تعداد انتخابی کلمات برای پنجره کشویی ۱، ۳، ۵، ۷ و ۹ است. تکرارهای CNN 200 و اندازه کانولانس هسته ۱۰۰ است. همانطور که در شکل ۳ نشان داده شده است، وقتی تعداد کلمات برای پنجره کشویی ۷ است، دقت و یادآوری الگوریتم (CNN-UDRP (T-data به ترتیب ۰٫۹۵ و ۰٫۹۸ است. و دقت و فراخوانی الگوریتم CNN-MDRP (S & T-data) 0.95 و ۱٫۰۰ است. این نتایج همه بالاتر از تعداد دیگری از کلمات برای پنجره کشویی را انتخاب می شود. بنابرا
ین، در این مقاله تعدادی از کلمات برای پنجره کشویی را با تعداد ۷ عدد انتخاب شده است.
ج) بررسی تعداد تکرار:
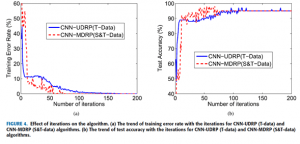
تغییر میزان خطای آموزش و دقت آزمایش را همراه با تعداد تکرارها ارائه می شوند. همانطور که در شکل ۴ نشان داده شده است، با افزایش تعداد تکرارها، نرخ خطای آموزش الگوریتم (CNN-UDRP (T-data به تدریج کاهش می یابد، در حالی که دقت آزمون این روش افزایش می یابد.
الگوریتم CNN-MDRP (S & T-data) روند مشابهی در رابطه با میزان خطای آموزش و دقت آزمایش دارد. در شکل ۴ همچنین می توانیم وقتی تعداد تکرارها ۷۰ باشد، روند آموزش (CNN-MDRP (S & T-data الگوریتم پایدار باشد در حالیکه الگوریتم (CNN-UDRP (T-data هنوز پایدار نیست. به عبارت دیگر، زمان آموزش الگوریتم MDRP S & T-data کوتاه تر است.
یعنی سرعت همگرا الگوریتم (CNN-MDRP (S & T-data سریع تر است.
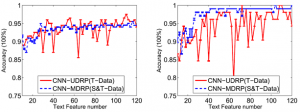
د) اثر انتخاب ویژگی های متنی:
تعداد ویژگی های استخراج شده از داده های ساختاری مشخص است، به عنوان مثال ۷۹ ویژگی. با این حال، تعداد مشخصی از داده های متنی بدون ساختار استخراج شده توسط CNN نامعلوم است. به این ترتیب، اثر شماره متن را بر دقت و فراخوانی الگوریتم های (CNN-UDRP (T-data و (CNN-MDRP (S & T-data بررسی شده است. استخراج ۱۰و ۲۰و …و۱۲۰ ویژگی از متن با استفاده از CNN در شکل ۵ دقت و فراخوانی هر ویژگی را پس از ۲۰۰ بار تکرار نشان می دهد. از شکل ۵ (a) و شکل ۵ (b)، زمانی که تعداد مشخصه متن کمتر از ۳۰ است، دقت الگوریتم های (CNN-UDRP (T-data و (CNN-MDRP (S & T-data کوچکتر از تعداد مشخصی از متن است که به طور واضح بزرگتر از ۳۰ است. این به این دلیل است که قادر به توصیف تعداد زیادی از اطلاعات مفید موجود در متن نیست، در حالی که تعداد مشخصه متن نسبتاً کوچک است. علاوه بر این، در شکل ۵ (a)، دقت الگوریتم(CNN-(MDRP (S & T-data پایدار تر از الگوریتم (CNN-UDRP (T-data است، یعنی الگوریتم (CNN-MDRP (S & T-data پس از اضافه کردن اطلاعات ساختاری کاهش می یابد. همانطور که در شکل ۵ (ب) نشان داده شده است، پس از اضافه کردن داده های ساختاری، فراخوانی الگوریتم بیشتر از الگوریتم (CNN-UDRP (T-data است. این نشان می دهد که فراخوانی الگوریتم بعد از اضافه کردن داده های ساختاری بهبود یافته است.
بررسی و تحلیل نتایج نهایی :
بررسی داده های ساختاری (S-Data):
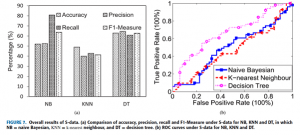
برای S-data، از الگوریتم های یادگیری ماشین سنتی، یعنی الگوریتم NB، KNNand DT استفاده شده است تا خطر ابتلا به سکته مغزی پیش بینی شود. طبقه بندی NB یک طبقه بندی ساده احتمالی است. این نیاز به محاسبه احتمال ویژگی های ویژگی دارد. در این آزمایش، از فرمول احتمالات شرطی برای ارزیابی ویژگی های ویژگی گسسته و توزیع گاوسی برای ارزیابی ویژگی های ویژگی پیوسته استفاده می کنیم. طبقه بندی KNN یک مجموعه داده آموزش داده شده است و نزدیکترین نمونه k در مجموعه داده های آموزشی پیدا شده است. برای KNN، لازم است که اندازه گیری فاصله و انتخاب مقدار k را تعیین کنید. در آزمایش، داده ها در ابتدا عادی می شوند. سپس از فاصله اقلیدسی برای اندازه گیری فاصله استفاده می کنیم. همانطور که برای انتخاب پارامترهای k، می بینیم که مدل بهترین زمانی است که k = 10. بنابراین، k = 10 را انتخاب شده است. نویسندگان مقاله از آنجایی که الگوریتم طبقه بندی و درخت رگرسیون (CART) در میان الگوریتم های درخت تصمیم گیری (DT) انتخاب کرده اند. برای تعیین بهترین طبقه بندی کننده و بهبود دقت مدل، روش تعلیق ۱۰ برابر برای مجموعه آموزشی مورد استفاده قرار می گیرد و داده ها از مجموعه آزمون در مرحله آموزش استفاده نمی شود. چارچوب اولیه مدل در شکل ۶ نشان داده شده است. نتایج در شکل ۷ (a) و شکل ۷ (b) نشان داده شده است. از شکل ۷ (a)، می توان دید که دقت سه الگوریتم یادگیری ماشین تقریبا حدود ۵۰٪ است. در میان آنها، دقت DT که ۶۳ درصد بالاتر است، به دنبال NB و KNN است. فراخوان NB برابر با ۰٫۸۰ است که بالاترین است و به ترتیب DT و KNN است. همچنین می توان از شکل ۷ (b) نشان دهیم که AUC مربوط به NB، KNN و DB به ترتیب ۰٫۴۹۵۰، ۰٫۴۳۶۶ و ۰٫۶۴۶۳ است. به طور خلاصه، برای S-data، طبقه بندی NB در آزمایش بهترین است. با این حال، مشاهده شده است که نمی توان به طور دقیق پیش بینی کرد که آیا بیمار در معرض خطر سکته مغزی با توجه به سن، جنس، آزمایشگاه بالینی و سایر اطلاعات ساختاری است. به عبارت دیگر، چون سکته مغزی یک بیماری با علائم پیچیده است، نمی توان پیش بینی کرد که آیا این بیمار در معرض خطر سکته مغزی تنها با در نظر گرفتن این ویژگی های ساده است.

بررسی داده های ساختاری و متنی (S & T-Data):
با توجه به بحث در بخش چهارم، Precision ، Recall در اندازه گیری F1 و منحنی ROC را بر اساس الگوریتم های CNN-UDRP (T-data و (CNN-MDRP (S & T-data ارائه شده است. در این آزمایش، تعداد انتخابی کلمات ۷ است و ویژگی متن ۱۰۰ است. همانطور که برای الگوریتمهای (CNN-UDRP (T-data و (CNN-MDRP (S & T-data، هر دو ۵ بار اجرا می شود و به دنبال میانگین آنها شاخص های ارزیابی به دست آمده است. از شکل ۸، دقت ۰٫۹۴۲۰ و فراخوان ۰٫۹۸۰۸ در زیر الگوریتم (CNN-UDRP (T-data است و دقت آن ۰٫۹۴۸۰ است و فراخوان ۰٫۹۹۹۲۳ در زیر الگوریتم (CNN-MDRP (S & T-data است. بنابراین می توان نتیجه گرفت که دقت الگوریتم های CNN-UDRP (T-data) و (CNN-MDRP (S & T-data تفاوت کمی دارد، اما فراخوانی الگوریتم (CNN-MDRP (S & T-data بیشتر است و همگرایی آن سرعت سریعتر است به طور خلاصه، عملکرد (CNN-MDRP (S & T-data بهتر از CNN-UDRP (T-data است.
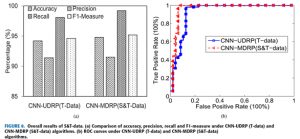
در نتیجه، برای مدلسازی ریسک بیماری، دقت پیش بینی خطر بستگی به ویژگی تنوع داده های بیمارستان دارد، یعنی بهتر است توصیف ویژگی بیماری، دقت بالاتر باشد. برای برخی از بیماریهای ساده، مانند hyperlipidemia، تنها چند ویژگی از داده های ساختاری می تواند شرح خوبی از بیماری را فراهم می کند، که نتیجه اثر نسبتا خوبی از پیش بینی خطر بیماری است. اما برای یک بیماری پیچیده مانند سکته مغزی که در مقاله ذکر شده است، تنها استفاده از ویژگی های داده های ساختاری، روش خوبی برای توصیف بیماری نیست. همانطور که از شکل ۷ (a) و شکل ۷ (b) دیده می شود، دقت متناظر کم است که تقریبا حدود ۵۰٪ است. بنابراین، در این مقاله، نه تنها داده های ساخت یافته بلکه همچنین داده های متنی بیماران را براساس الگوریتم پیشنهادی CNN-MDPR استفاده می کنیم. ما دریافتیم که با ترکیب این دو داده، میزان دقت می تواند به ۹۴٫۸۰٪ برسد، بنابراین بهتر است خطر ابتلا به سکته مغزی را ارزیابی شد.
نتیجه گیری :
در این مقاله، یک الگوریتم پیش بینی خطر بیماری های چندجمله ای مبتنی بر شبکه عصبی جدید CNN-MDRP را با استفاده از داده های ساختاری و غیر ساختاری از بیمارستان پیشنهاد شده است. به همین علت، هیچ کدام از کارهای موجود در هر دو نوع اطلاعات در زمینه تحلیل داده های بزرگ داده های طبیعی متمرکز نبودند. در مقایسه با چندین الگوریتم پیش بینی پیش بینی شده، دقت پیش بینی الگوریتم پیشنهادی با سرعت همگرا که ۹۴٫۸% درصد است که به مراتب سریع تر از الگوریتم پیش بینی معمول این حوزه جهت ریسک بیماری CNN-UDRP است.
دانشگاه آزاد اسلامی واحد تهران شمال
گردآورنده: دکتر سهیل تهرانی پور ” دانشجوی دکترای هوش مصنوعی ”