



شما بی رحمانه شبکه عصبی خود را با چپاندن اطلاعات عذاب می دهید. معمولا هنگام آموزش یک مدل گرادیان کاهشی از یادگیری ماشین،داده های آموزشی به صورت درهم و برهمی به دست می آید. که از این طریق ما مطمین می شویم که مدل در نقاط بهینه محلی گرفتار نمی شود.با این حال در سال ۲۰۰۹، Bengi و همکارانش یک مرتب سازی خاص سودمند را نمایش دادند. آنها رویکرد خود را یادگیری برنامه اموزشی (Curriculum Learning) نامیدند و نشان دادند داده های آموزشی که دارای نظم خاصی باشند، بهتر هستند.
با این ترتیب که مثال های ساده تر در ابتدای کار و مثال های دشوارتر در پایان کار آموزش دیده شوند.انها برای آزمایشاتشان ،از یک مدل قبلا اموزش دیده استفاده کردند،که به مدل اجازه می دهند تصمیم بگیرد چه داده ای سخت و چه داده ای آسان است.سپس یک مدل جدید روی مجموعه داده های منظم آموزش داده می شوند وبا دقت بالاتری نسبت به داده هایی که به طور تصادفی اموزش داده شدند، همگرا می شوند. در حین کار روی پروژه فعلی من ، به تکنیکی بنام Self-Paced Learning (SPL) رسیدم. این یک ایده جدید نیست و مقاله مربوطه به آن حدود ۱۰ سال پیش منتشر شده است.به هر حال ، این تکنیک بسیار جالب و هنوز هم مهم است زیرا به شما کمک می کند تا مدل گرادیان کاهشی تصادفی (SGD) به همگرایی سریعتر و حتی با دقت بالاتر برسد.
شهود استفاده شده در SPL:
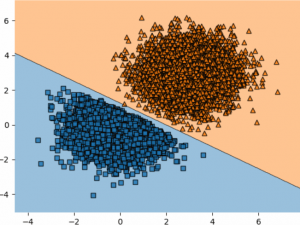
اصطلاح یادگیری خودآموز( Self-Paced ) از یک تکنیک یادگیری مورد استفاده توسط انسان سرچشمه گرفته شده است. به شما امکان می دهد سرعت خود را متناسب با الگوهای یادگیریتان تعریف کنید. SPL می تواند برای مطالعه یا آموزش یک مهارت خاص مانند ریاضی مورد استفاده قرار گیرد.برای اولین بار که شروع به یادگیری ریاضیات کردیم با شمارش اعدادشروع کردیم سپس جمع وتفریق را آموختیم. تا یک سن خاصی چیزی درباره ضرب ماتریس یا مشتقات نمی دانستیم. به همین روش ، SPL در یادگیری ماشینی، با مثالهای بسیار ساده ای شروع می کند و پس از یادگیری ، با موارد سخت تر ادامه می دهد که از “اصول اولیه” یاد گرفته شده بهره مند می شود. من SPL را به عنوان نوعی محدودکننده کار بر روی زمان تصور می کنم.یک کار طبقه بندی ساده را در یک فضای ۲ بعدی و یک مدل که به دو نقطه برای تقسیم فضا نیاز دارد . برای نمونه های آسان تر از محل تلاقی نقاط فاصله دارند. نمونه های سخت تر نزدیک به محل تلاقی هستند.حالت اولیه مدل یک خط در جایی از این فضا است.اگر فقط با نقاط داده آسان شروع کنیم ، مدل شیب هایی پیدا می کند که به آن می گویند در یک جهت خاص حرکت کند. اگر فقط با داده سخت شروع کنیم ، مدل ما می داند که این اشتباه است و راهی را برای رفتن به سمت خودش پیش می گیرد اما ممکن است دوباره از سمت طرف نقطه دیگر فاصله داشته باشد. محدود کردن نقاط به ناحیه مناسب ، به مدل کمک می کند تا از اضافه برداشتن داده ها و جلوگیری از همگرایی بیش از حد جلوگیری کند ، همانطور که زیر دیده می شود.
الگوریتم:
ترفند آن بسیار ساده است. از آستانه ای استفاده می کند ، که ما آن را lambda می نامیم. معمولاً، lambda با عددی نزدیک به صفر شروع می شود. با هر دوره ، lambda با یک عامل ثابت بیشتر از ۱ ضرب می شود.
به طور کلی ، این مقادیر با تکرارهای آموزش بیشتر کاهش می یابد زیرا مدل در روند کارهای آموزشی بهتر می شود و اشتباهات کمتری را انجام می دهد.آستانه lambda اکنون تعیین می کند که یک نقطه داده آسان یا سخت در نظر گرفته شود. هر زمان که از دست دادن یک نقطه داده در زیر لامبدا باشد ، یک نقطه داده آسان است. اگر بالاتر باشد ، سخت به نظر می رسد. در طول آموزش ، مرحله انتشار مجدد فقط در نقاط داده آسان انجام می شود و موارد سخت رد می شوند.از این رو ، مدل هر زمان که به اندازه کافی پیشرفت کرده باشد ، دشواری نمونه های آموزش را در طول آموزش افزایش می دهد.
مطمئناً ، در ابتدا ، این مدل ممکن است هیچ نقطه داده ای را آسان تشخیص ندهد و اصلاً آموزش نبیند.
بنابراین ، نویسندگان SPL یک مرحله به اضطلاح گرم کردن(warm-up) را معرفی کردند که در آن امکان رد کردن هیچ داده ای وجود ندارد و فقط یک زیر مجموعه کوچک از مجموعه آموزش استفاده می شود.
فرمول ریاضی:
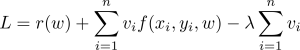
W=وزن مدل
r(w)=مورد استفاده جهت اجتناب از overfitting
V=یک متغیر که تصمیم می گیرد(x, y) ساده است یا دشوار.می تواند صفر یا یک باشد.
λ = استانه lambda
به طور خلاصه ، هرگاه “f (x, y , w)” ، از “lambda” کوچکتر باشد ، اولین مرحله “L” را با تنظیم “v” به “۱” بهینه می کنیم ، در غیر این صورت “۰”. مرحله دوم ، “v” را ثابت در نظر می گیرد و “w” را بهینه می کند. اگر”۱″ , “v” بود ، به روزرسانی مدل معمول انجام می شود ، به عنوان مثال ، انتشار مجدد. اگر “v” “0” باشد ، شیب های “f (x, y , w)”نیز “۰” خواهد بود و هیچ گونه بروزرسانی انجام نمی شود ( اما می توانید برای درک بهتر این مورد را نادیده بگیرید). برای تنظیم آستانه با مقدار بسیار کمی ، نتیجه ای حاصل نمی شود زیرا همه “v” ها “۰” خواهند بود زیرا از دست دادن هیچ نقطه داده ای زیر آستانه نخواهد بود. بنابراین ، نویسندگان SPL پیشنهاد کردند که برای تعداد مشخصی از تکرارها ، مرحله گرم کردن بدون SPL انجام شود و پس از آن با SPL شروع شود.
پیاده سازی PyTorch :
در مثال کد زیر ، نحوه اجرای SPL با PyTorch را در یک مجموعه داده ساختگی نشان می دهد. . برای تبدیل خروجی در احتمالات ، ما از یک تابع softmax استفاده می کنیم. در کد ، من از یک تابع log_softmax استفاده می کنم. به دلیل “عملکرد از دست دادن ” است که بعداً از آن استفاده می کنم. در پایان ، این مدل به همان شیوه گفته شده تا اینجا، آموزش می یابد.
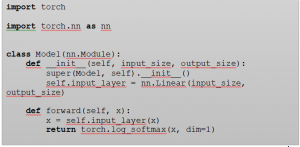
کد عملکرد را می توان در بخش بعدی مشاهده کرد. در اینجا ، ما از دست دادن هر نقطه را محاسبه می کنیم. اگراز دست دادن از آستانه کوچکتر باشد ، از دست دادن را با یک ضرب می کنیم ، در غیر این صورت با صفر. از این رو از دست دادن های ضرب شده در صفر هیچ تاثیری در آموزش ندارند.

کل پروژه را می توان در GitHub repository بیابید .
چرا همه از SPL استفاده نمی کنند؟دشوار بودن یافتن مقادیر اولیه مناسب شروع و در حال رشد برای آستانه طول می کشد زیرا این هیچ چیز عام نیست و بر اساس مدل ها ، توابع از دست دادن و مجموعه داده ها متفاوت است. برای مثالهایی که در این پست استفاده کردم ، مجبور شدم چندین بار تلاش کنم تا در نهایت تنظیمات مناسب را پیدا کنم. تصور کنید که شما یک مجموعه داده بسیار بزرگ و همچنین یک مدل بسیار بزرگ دارید. اساساً غیرممکن است که قبل از شروع اموزش واقعی ، کل پیشرفت را چندین بار بررسی کنید. با این وجود چندین روش دیگر برای یادگیری داده های آموزشی وجود دارد که متناسب با مجموعه های مختلف آموزشی است. با وجود این نکات ، ایده فعلی یک ایده بسیار شهودی بوده است که کار با آن را درک آسان و سرگرمی است.
ﻣﻨﺎﺑﻊ:
https://towardsdatascience.com/self-paced-learning-for-machine-learning-f1c489316c61
ﻧﺎم و ﻧﺎم ﺧﺎﻧﻮادﮔﯽ گردآوردنده: فائزه غلامرضائی
ﻣﻘﻄﻊ و رﺷﺘﻪ ﺗﺤﺼﯿﻠﯽ: ﮐﺎرﺷﻨﺎﺳﯽ ارﺷﺪ محاسبات نرم وهوش مصنوعی از دانشگاه شاهد
آدرس پروفایل لینکدین:
https://www.linkedin.com/in/faeze-gholamrezaie-96a587161/
ادرس ایمیل: faeze.gholamrezaie@shahed.ac.ir





