آموزش کتابخانه Pandas با بررسی دیتاست Titanic
|
آموزش کتابخانه Pandas با بررسی دیتاست Titanic سهیل تهرانی پور تابستان ۱۳۹۷ |
import pandas as pd
|
pd.read_csv() نحوه خواندن فایل با فرمت csv توسط pandas |
titanic_data = pd.read_csv("titanic.csv")
|
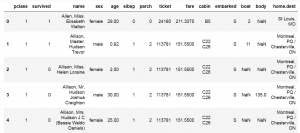
head()
نمایش ۵ داده اول ذخیره شده در دیتافریم |
در صورت ثبت عدد به عنوان پارامتر ورودی، همان تعداد داده از index های ابتدایی دیتافریم را نمایش خواهد داد.
titanic_data.head()
| shape
مشاهده ابعاد (سطر و ستون) دیتافریم |
titanic_data.shape
(۱۳۰۹, ۱۴)
|
Columns مشاهده عناوین ستون های دیتافریم |
titanic_data.columns
Index(['pclass', 'survived', 'name', 'sex', 'age', 'sibsp', 'parch', 'ticket',
'fare', 'cabin', 'embarked', 'boat', 'body', 'home.dest'],
dtype='object')
|
dtypes مشاهده عناوین ستون ها و تایپ داده هایشان |
titanic_data.dtypes
pclass int64 survived int64 name object sex object age float64 sibsp int64 parch int64 ticket object fare float64 cabin object embarked object boat object body float64 home.dest object dtype: object
|
info() اطلاعات کاملتر در مورد داده ها تعداد کل داده ها تمامی ستون ها به همراه تایپ داده هایشان هر ستون چه تعداد داده not-null دارد |
titanic_data.info()
<class 'pandas.core.frame.DataFrame'> RangeIndex: 1309 entries, 0 to 1308 Data columns (total 14 columns): pclass 1309 non-null int64 survived 1309 non-null int64 name 1309 non-null object sex 1309 non-null object age 1046 non-null float64 sibsp 1309 non-null int64 parch 1309 non-null int64 ticket 1309 non-null object fare 1308 non-null float64 cabin 295 non-null object embarked 1307 non-null object boat 486 non-null object body 121 non-null float64 home.dest 745 non-null object dtypes: float64(3), int64(4), object(7) memory usage: 143.2+ KB
| انتخاب سطر و ستون های خاص |
titanic_data['survived'][0:5]
۰ ۱ ۱ ۱ ۲ ۰ ۳ ۰ ۴ ۰ Name: survived, dtype: int64
titanic_data.survived[0:5]
۰ ۱ ۱ ۱ ۲ ۰ ۳ ۰ ۴ ۰ Name: survived, dtype: int64
| انتخاب ستون ها بر اساس چند عنوان مورد نظر |
titanic_data[['survived','age']][0:5]
| survived | age | |
|---|---|---|
| ۰ | ۱ | ۲۹٫۰۰ |
| ۱ | ۱ | ۰٫۹۲ |
| ۲ | ۰ | ۲٫۰۰ |
| ۳ | ۰ | ۳۰٫۰۰ |
| ۴ | ۰ | ۲۵٫۰۰ |
|
value_counts() پرینت داده های Unique در کل ستون |
titanic_data['survived'].value_counts()
۰ ۸۰۹ ۱ ۵۰۰ Name: survived, dtype: int64
| از بین بازماندگان ۳۳۹ نفر زن و تنها ۱۶۱ نفر مرد بوده اند. |
titanic_data['survived'].value_counts(normalize=True) * 100
۰ ۶۱٫۸۰۲۹۰۳ ۱ ۳۸٫۱۹۷۰۹۷ Name: survived, dtype: float64
| از بین بازماندگان ۳۳۹ نفر زن و تنها ۱۶۱ نفر مرد بوده اند. |
pd.crosstab( titanic_data.sex, titanic_data.survived )
| survived | ۰ | ۱ |
|---|---|---|
| sex | ||
| female | ۱۲۷ | ۳۳۹ |
| male | ۶۸۲ | ۱۶۱ |
| نرمالایز نمودن داده ها بر اساس سطرa |
pd.crosstab( titanic_data.sex, titanic_data.survived, normalize = "index" )
| survived | ۰ | ۱ |
|---|---|---|
| sex | ||
| female | ۰٫۲۷۲۵۳۲ | ۰٫۷۲۷۴۶۸ |
| male | ۰٫۸۰۹۰۱۵ | ۰٫۱۹۰۹۸۵ |
| نرمالایز نمودن داده ها بر اساس ستون |
pd.crosstab( titanic_data.sex, titanic_data.survived, normalize = "columns" )
| survived | ۰ | ۱ |
|---|---|---|
| sex | ||
| female | ۰٫۱۵۶۹۸۴ | ۰٫۶۷۸ |
| male | ۰٫۸۴۳۰۱۶ | ۰٫۳۲۲ |
|
نرمالایز نمودن کل داده ها
|
pd.crosstab( titanic_data.sex, titanic_data.survived, normalize = "all" )
| survived | ۰ | ۱ |
|---|---|---|
| sex | ||
| female | ۰٫۰۹۷۰۲۱ | ۰٫۲۵۸۹۷۶ |
| male | ۰٫۵۲۱۰۰۸ | ۰٫۱۲۲۹۹۵ |
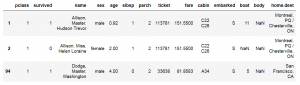
| لیست کودکان زیر ۵ سال برای ارایه به خانواده بازماندگان |
below_5_years = titanic_data[ titanic_data.age <= 5 ]
below_5_years[0:3]
| چه تعداد از مسافران کودک زیر ۵ سال بودند؟ |
len( below_5_years )
۵۶
| ۳۷ کودک از بین ۵۶ کودک زنده ماندند. |
titanic_data[ titanic_data.age <= 5 ]["survived"].value_counts( )
۱ ۳۷ ۰ ۱۹ Name: survived, dtype: int64
| نزدیک به ۲/۳ از کل کودکان زنده ماندند |
titanic_data[ titanic_data.age <= 5 ]["survived"].value_counts( normalize = True )
۱ ۰٫۶۶۰۷۱۴ ۰ ۰٫۳۳۹۲۸۶ Name: survived, dtype: float64
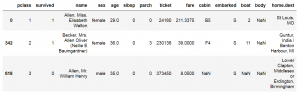
| از بین مسافرین، افراد با نام Allen را میخواهیم. |
titanic_data[titanic_data.name.str.contains( "Allen") ]
|
unique() داده های منحصر به فرد در هر ستون |
titanic_data.embarked.unique()
array(['S', 'C', nan, 'Q'], dtype=object)
| بررسی تعداد داده ها با مقدار NaN در ستون Embarked – محل نجات یا غرق شدن افراد مشخص نباشد |
titanic_data.embarked.value_counts(dropna=False)
S 914 C 270 Q 123 NaN 2 Name: embarked, dtype: int64
titanic_data.embarked.dropna().unique()
array(['S', 'C', 'Q'], dtype=object)
| dropna()حذف داده های بدون مقدار |
clean_titanic_data = titanic_data.dropna()
len( clean_titanic_data )
۰
|
استراتژی های پیشنهادی کار با دستور dropna()
حدف سطرهایی که در ستونشان NA دارند
|
clean_titanic_data = titanic_data.dropna( how = "all" ) len( clean_titanic_data )
۱۳۰۹
| حدف سطرهایی که در برخی از ستون هایشان NA دارند |
clean_titanic_data = titanic_data.dropna( subset = ['age','pclass'], how = 'any' ) len( clean_titanic_data )
۱۰۴۶
| نحوه تغییر نام یک ستون |
titanic_data.head( 2)

new_titanic = titanic_data.rename( columns = { 'row.names': 'rownum' },
inplace = True )
titanic_data.head(2)

| پرینت اطلاعات مربوط به جنسیت و سن و Pclass افرادی که زنده ماندند. |
titanic_data[ ( titanic_data.survived == 1 ) &
( titanic_data.age <= 5 ) ][['age',
'sex',
'pclass']][0:5]
| age | sex | pclass | |
|---|---|---|---|
| ۱ | ۰٫۹۲ | male | ۱ |
| ۹۴ | ۴٫۰۰ | male | ۱ |
| ۳۳۹ | ۱٫۰۰ | male | ۲ |
| ۳۴۰ | ۴٫۰۰ | female | ۲ |
| ۳۵۹ | ۰٫۸۳ | male | ۲ |
|
پرینت اطلاعات مربوط به جنسیت و Pclass افرادی که زنده ماندند و سن آن ها مشخص نبوده است.
|
titanic_data[ titanic_data.age.isnull() ][['age',
'survived',
'sex',
'pclass']][0:5]
| age | survived | sex | pclass | |
|---|---|---|---|---|
| ۱۵ | NaN | ۰ | male | ۱ |
| ۳۷ | NaN | ۱ | male | ۱ |
| ۴۰ | NaN | ۰ | male | ۱ |
| ۴۶ | NaN | ۰ | male | ۱ |
| ۵۹ | NaN | ۱ | female | ۱ |
| پرینت اطلاعات مربوط به جنسیت و Pclass افرادی که زنده ماندند و سن آن ها مشخص است. |
titanic_data[ -titanic_data.age.isnull() ][['age',
'survived',
'sex',
'pclass']][0:5]
| age | survived | sex | pclass | |
|---|---|---|---|---|
| ۰ | ۲۹٫۰۰ | ۱ | female | ۱ |
| ۱ | ۰٫۹۲ | ۱ | male | ۱ |
| ۲ | ۲٫۰۰ | ۰ | female | ۱ |
| ۳ | ۳۰٫۰۰ | ۰ | male | ۱ |
| ۴ | ۲۵٫۰۰ | ۰ | female | ۱ |
| نحوه ادغام و گروه بندی ستون های مختلف |
titanic_data.groupby( 'pclass' )['age'].mean()
pclass ۱ ۳۹٫۱۵۹۹۳۰ ۲ ۲۹٫۵۰۶۷۰۵ ۳ ۲۴٫۸۱۶۳۶۷ Name: age, dtype: float64
pclass_age_mean_df = titanic_data.groupby( 'pclass' )['age'].mean().reset_index() pclass_age_mean_df
| pclass | age | |
|---|---|---|
| ۰ | ۱ | ۳۹٫۱۵۹۹۳۰ |
| ۱ | ۲ | ۲۹٫۵۰۶۷۰۵ |
| ۲ | ۳ | ۲۴٫۸۱۶۳۶۷ |
pclass_gender_age_mean_df = titanic_data.groupby( ['pclass', 'sex'] )['age'].mean().reset_index() pclass_gender_age_mean_df
| pclass | sex | age | |
|---|---|---|---|
| ۰ | ۱ | female | ۳۷٫۰۳۷۵۹۴ |
| ۱ | ۱ | male | ۴۱٫۰۲۹۲۷۲ |
| ۲ | ۲ | female | ۲۷٫۴۹۹۲۲۳ |
| ۳ | ۲ | male | ۳۰٫۸۱۵۳۸۰ |
| ۴ | ۳ | female | ۲۲٫۱۸۵۳۲۹ |
| ۵ | ۳ | male | ۲۵٫۹۶۲۲۶۴ |
pclass_gender_survival_count_df = titanic_data.groupby( ['pclass', 'sex'] )['survived'].sum().reset_ index() pclass_gender_survival_count_ df
| pclass | sex | survived | |
|---|---|---|---|
| ۰ | ۱ | female | ۱۳۹ |
| ۱ | ۱ | male | ۶۱ |
| ۲ | ۲ | female | ۹۴ |
| ۳ | ۲ | male | ۲۵ |
| ۴ | ۳ | female | ۱۰۶ |
| ۵ | ۳ | male | ۷۵ |
pclass_age_gender_survival_df = pclass_gender_age_mean_df.merge( pclass_gender_survival_count_ df, on = ['pclass', 'sex'])
pclass_age_gender_survival_df
| pclass | sex | age | survived | |
|---|---|---|---|---|
| ۰ | ۱ | female | ۳۷٫۰۳۷۵۹۴ | ۱۳۹ |
| ۱ | ۱ | male | ۴۱٫۰۲۹۲۷۲ | ۶۱ |
| ۲ | ۲ | female | ۲۷٫۴۹۹۲۲۳ | ۹۴ |
| ۳ | ۲ | male | ۳۰٫۸۱۵۳۸۰ | ۲۵ |
| ۴ | ۳ | female | ۲۲٫۱۸۵۳۲۹ | ۱۰۶ |
| ۵ | ۳ | male | ۲۵٫۹۶۲۲۶۴ | ۷۵ |
| نحوه مربت سازی داده های دیتافریم |
pclass_age_gender_survival_df.sort_values( 'survived')
| pclass | sex | age | survived | |
|---|---|---|---|---|
| ۳ | ۲ | male | ۳۰٫۸۱۵۳۸۰ | ۲۵ |
| ۱ | ۱ | male | ۴۱٫۰۲۹۲۷۲ | ۶۱ |
| ۵ | ۳ | male | ۲۵٫۹۶۲۲۶۴ | ۷۵ |
| ۲ | ۲ | female | ۲۷٫۴۹۹۲۲۳ | ۹۴ |
| ۴ | ۳ | female | ۲۲٫۱۸۵۳۲۹ | ۱۰۶ |
| ۰ | ۱ | female | ۳۷٫۰۳۷۵۹۴ | ۱۳۹ |
pclass_age_gender_survival_df.sort_values( 'survived', ascending = False)
| pclass | sex | age | survived | |
|---|---|---|---|---|
| ۰ | ۱ | female | ۳۷٫۰۳۷۵۹۴ | ۱۳۹ |
| ۴ | ۳ | female | ۲۲٫۱۸۵۳۲۹ | ۱۰۶ |
| ۲ | ۲ | female | ۲۷٫۴۹۹۲۲۳ | ۹۴ |
| ۵ | ۳ | male | ۲۵٫۹۶۲۲۶۴ | ۷۵ |
| ۱ | ۱ | male | ۴۱٫۰۲۹۲۷۲ | ۶۱ |
| ۳ | ۲ | male | ۳۰٫۸۱۵۳۸۰ | ۲۵ |
نویسنده: دکتر سهیل تهرانی پور
سال: تابستان ۱۳۹۷