


Automatic labeling of continuous and discrete data clusters using An supervised Algorithm
I . بیان مساله :
مساله خوشه بندی یک مساله بسیار شناخته شده در زمینه یادگیری بدون ناظر است که این هم زیر مجموعه ای از یادگیری ماشین است. اکثر پژوهشگران بدنبال توسعه الگو ریتم خوشه بندی برای حل مشکلات مثل : محدودیت ها و داده در ابعاد بزرگ و غیر خطی بودن داده و… غیره هستن , اما کمتر کسی به سراغ تفسیر خوشه های ایجاد شده رفته . این مقاله یک متدلوژی معرفی می کند برای label کردن خوشه ها و کمک به متخصص . این label ها همان ویژگی های اصلی و مجموعه مقادیری هستن که مسئول و باعث ایجاد خوشه است. هدف کشف ارتباط بین ویژگی های موجود در یک خوشه بدون نیاز به ناظر و همچنین این که کدام ویژگی ها و چه مقادیر باعث ایجاد یک خوشه می شود.
II . راه حل های قبلی :
هدف label کردن خوشه ها خلاصه کردن تعریف و معنی خوشه ها بوده برای دستیابی به فهم بهتر از یک خوشه ; اما در برخی کار های گذشته برای افزایش سرعت و دقت برخی پژوهشگران از اصل موضوع دور شده .
۱ . P. Treeratpituk, J. Callan , Automatically labeling hierarchical clusters استفاده از روش hierarchical برای خوشه بندی و تقسیم خوشه ای به خوشه های کوچک تر . label ها در این کار محدود به اطلاعات متن بوده . اکثر توجه این مقاله بر روی خوشه بندی hierarchical بوده و نه label خوشه ها. در بسیاری از مقاله های این شکلی label های خوشه توانایی ارائه تعریف مناسبی برای خوشه را ندارند بلکه یک سری واژه تولید میکنند که برای فهم نیاز به متخصص دارد.
۲ . J. R. Quinlan, Induction of decision trees استفاده از قانون های دسته بندی برای تعریف یک خوشه خاص مناسب نیست چون این قوانین برای هر مساله خاص است و نه برای هر خوشه.
۳ . E. Glover, D. M. Pennock, Inferring hierarchical descriptions
۴ . O. Maqbool, H. Babri, Interpreting clustering results through cluster Labeling
۵ . H.-L. Chen, K.-T. Chuang, M.-S. Chen, On data labeling for clustering categorical data
۶ . T. Eltoft, R. J. P. de Figueiredo, A self-organizing neural network for cluster detection and labeling مقاله های ۵ و ۶ label کردن خوشه ها را به عنوان مساله label دهی به یک المان ناشناخته معرفی می کند .
III . نوآوری :
همانطور که در قسمت قبلی گفته شد , مقاله های زیادی در مورد labeling خوشه ها با روش خوشه بندی hierarchical نوشته شده اما اصل توجه آنها بر روی خود الگوریتم و روش خوشه بندی hierarchical بوده در نتیجه label های ایجاد شده بسیار مناسب نبوده و محتوای تعریفی نداشته. همچنین مقاله هایی که از درخت تصمیم و یا C4.5 استفاده کردن برای labeling بیشتر قانون هایی که استخراج شد مربوط به خود صورت مساله بوده و نه خوشه ها.
این مقاله بر روی مساله labeling خوشه متمرکز شده و بدنبال ایجاد label برای تعریف خوشه ها و استخراج اطلاعات مربوط به ویژگی هایی که خوشه مورد نظر را شکل می دهد است.
IV . راه حل پیشنهادی :
با توجه به database داده شده هر داده میتونه پیوسته یا گسسته باشه و اگر گسسته باشه گام اول discretization است سپس گام های بعدی برای هر نوع داده یکسان است :
۱ . خوشه بندی : داده ها را با الگوریتم بدون ناظر در خوشه های مناسب قرار می دهد.
۲ . با توجه به خوشه های ایجاد شده و با استفاده از الگوریتم با ناظر ویژگی های مهم تشکیل دهنده خوشه را تشخیص داده .
۳ . با اعمال strategy مناسب مقدار ویژگی های بدست آمده از گام قبلی را مشخص می کند و سپس از روی آن label مناسب برای هر خوشه را بدست می آورد.
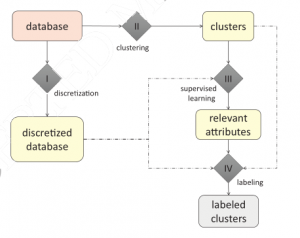
گام ۱ : Discretiaztion
در این گام اگر مقدار ویژگی بسیار بزرگ باشند در بازه های بسیار بزرگ قرار گیرند , برای هر ویژگی یک مقدار گسسته مشخص می کند . در نتیجه در گام ۳ الگوریتم با ناظر میتونه رابطه بین این ویژگی ها با پیچیدگی کمتر را به راحتی کشف کنه. استفاده از این روش باعث افزایش دقت و سرعت در زمان training می شود .
گام ۲ : Clustering
در این گام از الگوریتم بدون ناظر K-Means استفاده شده با K=3 در حالیکه می توان هر الگوریتم بدون ناظر دیگر نیز استفاده کرد. Labeling خوشه ها بر اساس خوشه های ایجاد شده انجام می شود پس اگر خوشه ها تغییر کنند label ها نیز تغییر می کنند.
گام ۳ : Supervised Learning
در این گام الگوریتم با ناظر مورد استفاده ( ANN ( Artificial Neural Network of MLP است. در اینجا ANN ها برای هر ویزگی تشکیل دهنده یک داده ایجاد می شود به تعداد خوشه ها.
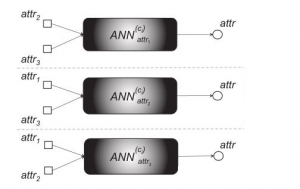
چون هر داده ۳ تا ویژگی دارد پس ۳تا ANN تشکیل می دهیم . هر یک از این ها مسئول پیدا کردن ارزش و ربط ویژگی مورد نظر برای قرار گرفتن به عنوان Label آن خوشه است. در اینجا هدف پیدا کردن ارتباط بین ویژگی هایی که ورودی شبکه قرار گرفته و ارتباطی که خروجی شبکه است با استفاده از ANN . برای هر خوشه ویژگی ارزیابی شده توسط ANN میتونه نماینده قرار بگیره برای بقیه ویژگی ها و در نتیجه ویژگی هایی که یک خوشه را تشکیل می دهد در این مرحله مشخص شده.
گام ۴ : Labeling
هدف پیدا کردن بازه ی ویژگی های انتخاب شده در گام قبلی است. برای نمایش اکثریت خوشه مقداری که برای ویژگی ها انتخاب می شوند مقادیری هستن با بیشترین رخداد ( frequency ) در آن خوشه. اگر discretization در ویژگی رخ داده باشه مقدار آن نشان دهنده محدوده بازه ای از مقادیر بدست آمده در discretization برای مقدار با بالاترین رخداد.
اگر discretization در ویژگی رخ نداده باشه مقداری که بیشترین رخداد را دارد نشان دهنده آن ویژگی است.
V . ارزیابی :
راه حل در Matlab شبیه سازی شده و بر روی داده های :
۱ . Identification of Glass
۲ . Identification of Wheat Seeds
۳ . identification of IRIS Plants
VI.نتایج :
۱ . در Identification of Glass , label های ایجاد شده برای خوشه ها تونستن به صورت میانگین ۹۵٫۵۴ % المان را دسته بندی کنند که بیشترین خطا دسته بندی را در خوشه ۵ با ۶ تا خطا از ۸۵ تا داشتیم با توجه به label داده شده به خوشه ۵ .
۲ . در Identification of Wheat Seedsl label, های ایجاد شده برای خوشه ها تونستن به صورت میانگین ۸۹ % المان را دسته بندی کنند که بیشترین خطا دسته بندی را در خوشه ۲ با ۱۲ تا خطا از ۸۲ تا داشتیم با توجه به label داده شده به خوشه ۲ .
۳ . در Identification of IRIS Plants label, های ایجاد شده برای خوشه ها تونستن به صورت میانگین ۹۴٫۱۴ % المان را دسته بندی کنند که بیشترین خطا دسته بندی را در خوشه ۲ با ۶ تا خطا از ۶۲ تا تا داشتیم با توجه به label داده شده به خوشه ۲ .
VII . کار های آینده :
- اعمال روش های دیگر برای discretization با مقادیر متفاوت R برای هر ویژگی .
- ایجاد classifier با label های کشف شده .
- ایجاد classifier از ANN هایی که ویژگی های مناسب در هر خوشه را تشخیص داده اند.
- استفاده از PCA برای به دست آوردن ویژگی های مناسب هر خوشه بجای ANN .
VIII . مزیت :
استفاده از discretization باعث می شود که نمایش یک خوشه فقط محدود به یک مقدار در یک ویژگی نباشد بلکه بتوان از بازهی مقادیر استفاده کرد.
IX . معایب :
پارامتر های وابسته به مسئله زیاد وجود دارند که با تغییر آنها جواب ها تغییر می کند مثل : نوع الگوریتم بدون ناظر و روش discretization و مقادیر R,M,V . …
نویسنده: معصومه سادات علوی





