


Age estimation using deep learning
بیان مسئله
این مقاله دقیقا چه مسئله ای را می خواهد حل کند ؟
در این پژوهش ما در صدد این هستیم که سن افراد را با استفاده از یادگیری عمیق (deep learning) ، شبکه های عصبی مصنوعی Auto encoder تخمین بزنیم . در اینجا تخمین سن با استفاده از تصاویر افراد انجام می شود ، برآورد سن از تصاویر چهره یک کار بسیار پیچیده است .
سن همیشه یک ویژگی مهم هویت است. و همچنین نیز یک عامل مهم در تعامل اجتماعی بوده است. برآورد سن از طریق تحلیل عددی، بسیاری از کاربردهای بالقوه مانند توسعه هوش مصنوعی ، بهبود ایمنی و حفاظت در بخش های مختلف مانند حمل و نقل، امنیت و پزشکی را پیدا می کند. در بسیاری از پژوهش ها ، محققان به خصوص در تحلیل ویژگی های چهره به کاهش سن رنج می برند. . هدف ما در اینجا ، برآورد اتوماتیک سن توسط یک ماشین در برنامه های کاربردی مفید است که هدف آن تعیین سن افراد بدون شناسایی آن ها است. پیشرفت های اخیر در تکنیک های هوش مصنوعی (AI) و تکنیک های یادگیری عمیق (DL) باعث افزایش انگیزه ها برای استفاده از این روش ها برای تخمین سن می شود.
|
DL = deep learning AI = Artificial intelligence |
چرا حل کردن این مسئله حائز اهمیت است ؟
در دهه های اخیر با افزایش نیاز به سیستم های تشخیص و نظارت خودکار، تجزیه و تحلیل چهره های انسانی بیشترین موضوعات مورد علاقه در زمینه بینایی کامپیوتری مانند تشخیص چهره، طبقه بندی جنسیتی و تشخیص صورت است. در این چارچوب، تحقیقات در تکنیک های تخمین سن پیشرفت کرده اند.
اخیرا، سن انسان، یک نشانه ی مهم در بسیاری از برنامه های کاربردی مانند تخمین سن در تحقیقات جرم، بازاریابی هدفمند سازگار با سن، مشتری الکترونیکی، مدیریت ارتباطات، سرگرمی برای سیستم های توصیه شده،کنترل دسترسی امنیتی، بیومتریک، تبلیغات دقیق، نظارت هوشمند، کنترل دسترسی به اینترنت، طبقه بندی قومیت، تجزیه و تحلیل رسانه های اجتماعی، پزشکی، روانشناسی، و تعامل کامپیوتر و انسان . در واقع، سن یک کانال اصلی اطلاعات غیر کلامی است که می تواند به محققان در این حوزه کمک کند تا عملکرد و کارایی رابط های جدید را بهبود بخشد.
فرضیات مسئله
برای اینکه مسئله قابل حل باشد چه فرضیاتی به کار رفته اند ؟
از جمله فرضیات به کار رفته می توان به موارد زیر اشاره کرد :
دو نفر می توانند به طور متفاوتی رشد کنند، چرا که فرآیند پیری نه تنها به وسیله ژن های فرد تعیین می شود، بلکه از طریق بسیاری از عوامل خارجی مانند سلامت، شیوه زندگی، محیط و شرایط نیز تعیین می شود. همچنین حالت صورت، چین و چروک صورت و … همه عناصری هستند که پیش بینی سن کاربر را آسان می کنند. همینطور از مشکلات تخمین سن می توان به این مورد اشاره کرد که در بزرگسالی تغییر قابل توجه پیری پوست (تغییر در بافت) و تغییر شکل چروک ادامه دارد. همچنین، مردان و زنان به طرق مختلف متفاوت هستند.
راه حل های قبلی
روش های دیگران برای حل این مسئله به چند دسته تقسیم می شوند؟
چندین روش برای برآورد سن کاربر به صورت اتوماتیک ارائه شده است. یک طرح معمول از روش های موجود برای تخمین سن معمولا شامل دو مرحله می شود: اول عکس فردی است که ویژگی های تصویر و بازنمودها را برای سن استخراج می کند و دوم، یادگیری سنسور سن با استفاده از این ویژگی های تصویر است.
در سال ۱۹۹۸ Kwon و همکارانش از یک مجموعه داده کوچک با ۴۷ تصویر برای تخمینی سن با استفاده از مدل های تنسنجی (Anthropometric) و الگوی چین و چروک استفاده کردند. گروه سنی که در نظر داشتند کودکان ، جوانان و سالخوردگان بود . همچنین ظاهر صورت را از رو به رو در نظر گرفته بودند.
در سال ۲۰۰۲، لانیت با توجه به نتایج آزمایش هایشان بعضی از قسمت های صورت و به ویژه منطقه اطراف چشم، که منبع قابل توجهی از اطلاعات برای وظیفه تخمین سن اتوماتیک است را پیشنهاد داد . نام متد آن ها AMM بود همچنین مجموعه داده های آن ها ۲۵۰ عکس برای آموزش و ۸۰ عکس برای تست ، محموده سنی بین ۱ تا ۱۸ سال را انتخاب کرده بودند .
در سال ۲۰۰۷، شین و همکاران، از مجموعه داده های MORPH و FG-Net برای تجزیه و تحلیل خطی خطی LDA و طبقه بندی سنی KNN استفاده کردند. روش به نام AGES را ارائه دادند.
و همینطور آخرین مدلی که در سال ۲۰۱۷ ارائه شده است توسط زکریا قاواقنه و همکارانش : که یک الگوریتم جدید برای طبقه بندی سن و جنس بشر، تصاویر ذهنی و چهره را با استفاده از CNN برای استخراج و طبقه بندی ویژگی ها بود. متد آن ها DNN و DATASET آن ها نیز ADIENCE بود .
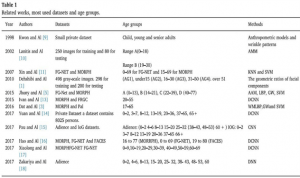
برخی از آثار مرتبط، روش ها، محدوده های سنی و مجموعه داده های مورد استفاده در تخمین سن می توانند در جدول ۱ خلاصه شوند.
نوآوری
نوآوری های این مقاله چه هستند؟
نوآوری این مقاله استفاده از یادگیری Supervised در تخمین سن است . همانطور که اشاره شده کارهای قبلی در تخمین سن به صورت Unsupervised بوده است.
از نوآوری های دیگر می توان به استفاده از Sparse Auto Encoder به جای Auto Encoder اشاره کرد. با توجه به نتایج بدست آمده مشخص شده است که استفاده از دو مورد ذکر شده باعث افزایش دقت در تخمین سن افراد می شود.
راه حل های پیشنهادی
برای حل مساله، با توجه به فرضیات به کار رفته چه راه حلی پیشنهاد شده است؟
در این مقاله، یک روش جدید تخمین سن مبتنی بر معماری DL به نام (DSSAE) پیشنهاد شده است، همانطور که در شکل ۱ نشان داده شده است.
کار به دو مرحله تقسیم می شود:
اول تهیه داده ها است؛ تشخیص چهره و چرخش به دور صورت.
دوم طبقه بندی است که با استفاده از Auto encoder نظارت شده صورت می گیرد .
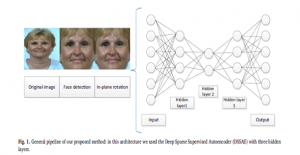
مراحل روش پیشنهادی ما که در شکل ۱ مشخص است : در این معماری ما از (DSSAE) با سه لایه پنهان استفاده کردیم .
اولین گام ما جدا کردن یا بیرون کشیدن صورت از تصویر می باشد که این عمل با استفاده از الگوریتم (Ada Boost) که در سال ۲۰۰۱ ارائه شده است استفاده می کنیم. این الگوریتم بر اساس اصل “تقویت” است که شامل جمع آوری چندین طبقه بندی ضعیف برای دستیابی به سیستم با ظرفیت بالا است. در شکل ۲ می توانید تصویر برش داده شده پس از استخراج با الگوریم (Ada Boost) را مشاهده کنید .

موقعیت سر، عامل مهمی در تخمین سن است. در حقیقت، با توجه به احساسات و پوزیشن ها هنگام گرفتن تصویر سر به صورت می تواند بر عملکرد الگوریتم تاثیر بگذارد، لازم است جهت گیری را تنظیم کنید. برای حل این مشکل پیشنهاد می کنیم که جهت گیری سر را از طریق موقعیت چشم ها تنظیم کنید. بنابراین موقعیت چشم را استخراج می کنیم.پس از تشخیص موقعیت چشم چپ و راست ما فرمول زیر را برای زاویه چرخش استفاده می کنیم.

| DSSAE = Deep Sparse Supervised Auto Encoder |
جایی که ( ، ) و ( ، ) موقعیت های تشخیص چشمی راست و چپ را نشان می دهند. شکل ۳موقعیت چشم، موقعیت سر و موقعیت تنظیم شده را ارائه می دهد.

Auto encoder پیشنهادی:
هدف از Auto encoder این است که بین داده های ورودی برخی از همبستگی ها به منظور کاهش اندازه این داده ها و طبقه بندی آنها پیدا شود. روش کدگذاری ضعیف، مدل دیگری است که به دنبال بازنمایی خوب است. اصطلاح sparse به این معنی است که ما می خواهیم نورون های پنهان یک احتمال برای فعال شدن داشته باشند. تعداد نورونهای لایه های پنهان کوچکتر از لایه های ورودی و خروجی است.
تابع بهینه سازی sparce auto encoder به صورت زیر می باشد :
![]()
جایی که m تعداد گره های پنهان است، و یک ضریب است که وزن مجازات جبهه را تعیین می کند. پارامتر sparsity است ، به عبارت دیگر، آن را برای هدف متوسط فعال کردن واحدهای پنهان است، که معمولا یک مقدار کوچک نزدیک صفر است:
![]()
واگرایی Kullback-Leibler به صورت زیر تعریف می شود:
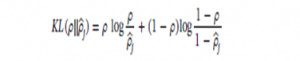
هدف آموزش در Auto encoder اسپرد برای یافتن پارامترهای مناسب برای به حداقل رساندن تابع هدف معادله معادله است. جایی که الگوریتم های back propagation به طور کلی برای آموزش مدل استفاده می شود. به ویژه، انتخاب تعداد مناسب گره های پنهان در مدل نقش بسیار مهمی در دستیابی به عملکرد بالا از الگوریتم یادگیری عمیق را بازی می کند. یادگیری تحت نظارت یکی از الگوریتم های قدرتمند در AI است، در پردازش تصویر، تشخیص گفتار، تشخیص کد پستی و شناسایی الگو بسیار قوی بود.
راه حل ما برای فرایند طبقه بندی در این کار، استفاده از sparse supervised auto encoder است. در ابتدا، ما پیشنهاد می کنیم ویژگی هایی را یاد بگیریم که از آنها یک امضای اسپارتی در یک کلاس دارند. که برای این کار از استاندارد L1 که توسط ، ماجومدار و همکارانش ارائه شد و به شرح زیر است استفاده می کنیم:
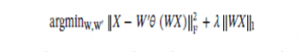
جایی که λ نامیده می شود، با استفاده از اصلاح L1-norms، اصطلاح تنظیم می شود.
با این حال، در سناریوهایی که داده های آموزشی برچسب دار در دسترس هستند و می توانند برای آموزش استفاده شوند، فرموله پیشنهاد شده می تواند برای رمزگذاری اطلاعات تبعیض آمیز استفاده شود. برای انتقال از یادگیری بدون نظارت به با نظارت، ابتدا داده های آموزشی به ما معرفی شود:
![]()
ارزیابی
راه حل های پیشنهادی روی چه داده هایی پیاده سازی شده اند ؟
ما از مجموعه داده های MORPH، FGNET برای تست عملکرد روش پیشنهادی مان استفاده می کنیم. پایگاه داده MORPH شامل ۵۵،۰۰۰ تصویر منحصر به فرد از بیش از ۱۳،۰۰۰ نفر، از سال ۲۰۰۳ تا اواخر سال ۲۰۰۷ است. رنج سنین از ۱۶ تا ۷۷ با میانگین سن ۳۳ سالگی است. میانگین تصاویر در هر فرد ۴ و میانگین بین عکس ها ۱۶۴ روز است که حداقل ۱ روز و حداکثر ۱۶۸۱ روز است. پایگاه داده تشخیص چهره و ژست (FG-NET) شامل ۱۲ عکس از سنین مختلف بین ۰ و ۶۹ است. در مجموع، یک مخلوط از ۱۰۰۲ رنگ و تصاویر خاکستری وجود دارد که در محیط های کاملا کنترل نشده گرفته شده اند. هر کدام به صورت دستی با ۶۸ نقطه برجسته توضیح داده شد. علاوه بر این فایل داده ای برای هر تصویر وجود دارد که حاوی نوع، کیفیت، اندازه تصویر و اطلاعات مربوط به موضوع مانند سن، جنسیت، عینک، کلاه، سبیل، ریش و پوزیشن است.
یک مشکل خاص با این مجموعه داده این واقعیت است که تصاویر در طول سال به طور مساوی توزیع نمی شوند و بنابراین تنها تعداد کمی از تصاویر از افراد بالای ۴۰ سال در دسترس هستند.
در جدول ۳ می توانید برخی اطلاعات از جمله تعداد زن و مرد ، رده سنی و تعداد عکس ها را مشاهده کنید.

همچنین در شکل ۵ نمونه هایی از تصاویر چهره با مقادیر مختلف سنی از MORPH (a) و FG-NET (b) را ملاحضه می کنید.

نتایج
نتایج شبیه سازی چگونه بوده است؟
اولین ارزیابی : جدول ۴ نتایج MAE برخی از روش های با استفاده از معماری مختلف DL در مقایسه با روش ما را لیست می کند.
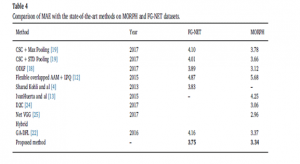
در واقع جدول ۴ متد ما با برخی از روش های پیشرفته دیگر را مورد ارزیابی قرار داده. تفاوت عمده در MAE در طبقه بندی عمیق بسیار جالب است. نتیجه در جدول ۴ نشان دهنده استحکام روش ما در مقایسه با سایر آثار است، روش ما نرخ مهمی از MAE را نشان می دهد که در جدول نشان داده شده است.
ازیابی بعدی :
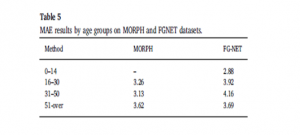
روش پیشنهادی نیز توسط گروه های سنی مورد آزمایش قرار گرفت. ما سنها را به چهار دسته تقسیم می کنیم، کودکان (۰-۱۴) جوانان (۱۶-۳۰)، ارشد (۳۱-۵۰) و سالمندان (۵۱ بیش از). جدول ۵ ارزیابی روش ما را در هر دسته با استفاده از نرخ MAE ارائه می دهد. این رویکرد نشان داد که عملکرد در گروه های کودک و نوجوانان، MAE بهترین نتیجه را با کمتر از ۲٫۸۸ و ۳٫۹۲ برای مجموعه داده های FG-NET و ۳٫۲۶ برای MORPH ارائه می دهد.
همچنین روش پیشنهادی با استفاده از نمره تجمعی ارائه شده به شرح زیر ارزیابی شد:
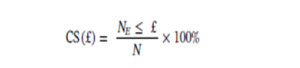
این یک معیار ارزیابی استاندارد برای مسئله تخمین سن از زمان آغاز تحقیق تخمین سن است. این روش ارزیابی در بسیاری از آثار قبلی مورد استفاده قرار گرفته است.
شکل ۶ منحنی های CS روش برآورد سن برای سن برای ۰ تا ۲۰ سال برای پایگاه داده FG-NET را نشان می دهد. بر اساس نتایج، ما نتیجه گرفتیم که مدل ما یک عملکرد بسیار رقابتی را نشان می دهد که اثربخشی روش پیشنهادی را نشان می دهد.

در ارزیابی بعدی کارمان، ما نتیجه نتایج MAE بین DSSAE پیشنهادی و Auto Encoders انباشته شده (DSAE) را با توجه به شکل ۷ مقایسه می کنیم.

از آنجایی که مدلهای DL برای بسیاری از مشکلات طبقه بندی مانند تشخیص گفتار، تشخیص چهره، شناخت احساسات، در این بخش، عملکرد چالشی را نشان دادند، ما چارچوب پیشنهاد شده را با چندین مدل محبوب از طبقه بندی های دیگر مقایسه می کنیم.نتیجه ای که در جدول ۶ نشان داده شده، کارایی الگوریتم DL را در مقایسه با الگوریتم های طبقه بندی کلاسی نشان می دهد.
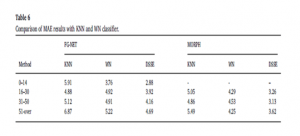
DL میزان قابل توجهی از MAE را در مقایسه با طبقه بندی های کلاسیک (KNN-WN) ارائه می دهد. DNN عملکرد بهتر برای تخمین سن نسبت به شبکه های عصبی کم عمق را نشان می دهد.
کارهای آینده
آیا مقاله پیشنهادی برای ادامه کار داشته است ؟ اگر نداشته پیشنهاد شما چیست؟
محورهای توسعه آینده می تواند شامل ترکیبی از ویژگی های گفتاری و صورت با استفاده از DSSAE برای تخمین سن می باشد.
نقاط قوت
از دیدگاه شما نقاط قوت انجام شده در این مقاله از جهت ایده نحوه ی ارزیابی و فرضیات چه هستند؟
از نقاط قوت می توان به ارائه ۰ تا ۱۰۰ ، Auto Encoder پیشنهادی اشاره کرد. این کار باعث می شود پیاده سازی این متد ساده تر شود. همچنین فرضیه های ارائه شده توسط محققان در حوزه سن کاملا منطقی است.
نقاط ضعف
از دیدگاه شما نقاط ضعف این مقاله چه هستند؟
محققان می توانستند برای ارزیابی ، متد خود را با روش های بیشتری مورد مقایسه قرار دهند.
دانشگاه آزاد اسلامی واحد تهران شمال
موضوع : گزارش تحقیقاتی
استاد محترم : دکتر منثوری
نام و نام خانوادگی گرداورنده : نوید آتش فراز
سال پذیرش : May 2018
ژورنال : Computers and Electrical Engineering






