



Linear Maximum Margin Classifier for Learning from Uncertain Data
بیان مسأله
این مقاله به دنبال این است که یک روش کلاسیفایر جدید ارائه کند که این کلاسیفایر بتواند دقت بالاتری را نسبت به حالت معمولی داشته باشد. مبنای کار SVM است و بهبود روی SVM اصلی است. این مقاله SVM را بگونه ای بازفرموله کرده است که هر داده نمونه توسط توزیع گوسی چندبعدی مدل شود. این توزیع با بردار میانگین و ماتریکس کوواریانسش تفسیر می شود و این ماتریکس کوواریانس عدم قطعیت را مدلسازی می کند.
کلاسیفایرها یکی از تکنیک های حل مسائل طبقه بندی است و بهبود دقت آن ها میتواند به هوشمندی سیستم کمک کند. بنابراین این مقاله به دنبال این است که دقت را بهبود داده و تکنیکهای بهتری را برای حل مسأله ارائه دهد. عدم قطعیت مسأله فراگیری است که در تمام زمینه های علمی وجود دارد. روز بروز بر میزان داده های نامطمئن افزوده می شود. مدیریت دسته بندی و کار با این نوع داده نیازمند ارائه روشی است که بتواند عدم اطمینان را حل کند. محققان مسئله عدم اطمینان در یادگیری با ناظر را از جهات مختلف مورد بررسی قرار داده اند.
فرضیات مسأله
عدم قطعیت در داده را میشود از طریق توزیع گوسی چند متغیره مدل کرد و اینکه دقت کلاسیفایر را میشود با استفاده از توزیع گوسی بهبود داد. نگارندگان فرض کرده اند که داده های آموزشی دارای توزیع گاوسی یا نرمال چند متغییره هستند و میانگین و ماتریسک کوواریانس داده ها مشخص است. هر نمونه ماتریکس کووارانس متفاوت دارد که بیانگر عدم اطمینان حول میانگین آن است.
راه حل های قبلی
لیو و تایو مسئله دسته بندی را در داده هایی که بصورت تصادفی حذف شده بودند مطالعه کردند. در این سناریو، داده های مشاهده نشده با برچسب های بدون نویز وجود داشت. اگرچه، قبل از مشاهده شدن، برچسب های صحیح بصورت مستقل با احتمال ( P(۰,۰٫۵ جابجا شدند و نویز برچسب های تصادفی نسبت به کلاس وطبقه شرطی شد. تزلیپسی و همکاران یک SVM توسعه یافته (تغییر یافته) که به هر نمونه آموزشی درجه بین (۰و۱) می دهد و بیانگر میزان قطعیت تعلق آن نمونه به دسته مورد نظر است را پیشنهاد دادند. لی و سیثی رویکرد یادگیری فعال که مبتنی بر شناسایی و برچسب زنی نمونه های نامطمئن است را پیشنهاد دادند. روش آنها مقادیر نامطمئن برای هر نمونه ورودی را براساس امتیاز خروجی آن از دسته بند تخمین می زند و تنها نمونه هایی را انتخاب می کند که عدم قطعیت آنها بالاتر از حد تعریف شده توسط کاربر باشد. سارافیس از وزن دهی برای کمی کردن برچسب زنی اتوماتیک برچسب های آموزشی به تصاویر استفاده کرد و نشان داد که این وزند هی با SVM فازی و power SVM می تواند منجر به بهبود بازیابی اطلاعات در مقایسه با SVM استاندارد شود. بی و ژانگ فرمولی آماری را استفاده کردند که نویز ورودی بصورت جز مخلوط مخفی در نظر گرفته می شود.ولی با این روش فرض مستقل بودن و توزیع یکسان داشتن داده های آموزشی نقض می شود. در آن تحقیق عدم قطعیت بصورت ایزوتروپیکی مدل سازی شد. محققان دیگر از روش برنامهسازی مخروط دوگانی (SOCP) استفاده کردند. از روش بهینهسازی استوار نیز هنگامی که داده ها مشخص نیستند استفاده شد. لانکریت و همکاران در روش طبقه بندی دو کلاسه، مسئله مینیماکس را طوری فورموله کردند که بیشترین احتمال طبقه بندی اشتباه داده های بعدی کمینه شود. شیواسوامی و همکاران از فرموله کردن SOCP به همراه استفاده از نابرابری چبیشف تعمیم یافته جهت ارایه یک دسته بند مقاوم استفاده کردند. در چندین تحقیق از روش عدم قطعیت نوع جعبه ای (Box type) استفاده شد. زو و همکاران از روش عدم قطعیت غیر جعبه ای استفاده کردند. کی و همکاران از ماشین بردار پشتیان دوقلوی مقاوم سازی (TWSVM) شده استفاده کردند. این SVM داده های دارای نویز اندازه گیری را با استفاده از فرمولاسیون SOCP دسته بندی می کند. در داده های آنها داده های ورودی با نویز ایزوتروپیک آلوده شدند (برای مثال جابجایی فضایی در نمونه داده های آموزشی) و ازاینرو نتوانستند عدم قطعیت واقعی را که الگوهای نویز پیچیده تری دارد مدلسازی کنند. روش های قبلی فرض مستقل با توزیع یکسان (آی آیدی) بودن را برای داده های ورودی آموزش را نقض می کنند J. Bi and T. Zhang نمی توانند عدم قطعیت را در هر نمونه آموزشی ورودی مدل سازی کنند. امکان مدلسازی ناهمسانگرد (Anisotropic) عدم قطعیت را نمی دهند.
نوآوری ها
.۱٫ارائه طبقه بندی که فرض مستقل با توزیع یکسان (آی آیدی) بودن داده ها را نقض نمی کند و می تواند عدم قطعیت در هر نمونه ورودی آموزشی با استفاده از ماتریکس دلخواه کوواریانس را مدل سازی کند (امکان مدلسازی ناهمسانگرد را می دهد).
.۲٫تعریف یک تابع هزینه محدب که مشتقات آن نسبت به پارامترهای ناشناخته ابرصفحه جدا کننده می تواند بشکل عبارت بسته بیان شود.
.۳٫بهبودی در تابع هزینه ایجاد کرده است که دقت کلاسیفایر را بهبود بخشیده است.
.۴٫استفاده از عدم قطعیت داده ها در بهبود طبقه بندی با استفاده از اضافه کردن یک جمله در تابع هزینه
راه حل پیشنهادی
در این مقاله:
ماشین بردار پشتیبان با نمونه های عدم قطعیت گوسی
چارچوب یادگیری باناظری را در نظر میگیریم و مجموعه آموزشی را با
![]()
نشان میدهم که در آن Xi نمونه آموزشی و Yi برچسب مربوط به کلاس آن است.
SVM خطی استاندارد ابرصفحه زیر را یاد میگیرد:
H: wTx + b = 0
که تابع هدف زیررا نسبت ب W و b کمینه می کند:
![]()
فرمول ۱تابع هزینه ی SVM است که Hinge نام دارد.
![]()
فرمول ۲تابع هزینه SVM GSU است.
با مقایسه ی این ۲فرمول در میابیم که عبارات اضافه شده به فرمول اصلی روند بهبوددهی SVM اصلی میباشد که از توزیع گوسی استفاده کرده است.

در SVM GSU خط فاصله اش را با محدوده بیضی حفظ میکند بیضی همان عدم قطعیت Uncertainty است. در واقع خطی که می اندازد فاصله اش با محدوده ی بیضی ماکسیمم شود نه داده ها.
ارزیابی
برای ارزیابی کلاسیفایر معیارهای متفاوتی داریم همانند Recall و Accuracy و … در این مقاله از Accuracy استفاده شده است و همانطور که میدانیم در بحث کلاسیفایر فقط به یک معیار نمیتوان تکیه کرد. معیار دقت (Accuracy) که نسبت مشاهدات صحیح بر مجموع مشاهدات است.
نتایج
ارائه یک دسته بند تازه که تحت پارادایم، SVM عدم قطعیت موجود در داده ها را در نظر گرفته و نسبت به SVM استاندارد و توسعه های دیگر SVM که عدم قطعیت را بصورت ایزوتروپیک مدل می کنند و دیگر مدل های جدید و پشرفته بهتر عمل می کند. این روش بر روی داده های مصنوعی و۵ دیتاست اعمال شد. دیتاست های ,MNIST , WDBC , DEAP جز دیتاست های استاندارد وTRECVID MED و TV News Channel Commercial Detection محبوب در حوزه هوش مصنوعی هستند. اگر دیتاست نویزی نداشته باشد محققان بصورت مصنوعی در آن نویز ایجاد کرده اند تا مناسب موضوع تحقیق باشد.

این شکل نشان دهنده ی این است که هرچه تعداد نمونه ها افزایش میابد SVM GSU همانند SVM اصلی عمل می کند. در نتیجه درمیابیم که این روند بهبودی که پیش گرفته شده است در تعداد داده ی کم میتواند به خوبی عمل کند.
مثال دقت برخی از دیتاست ها:
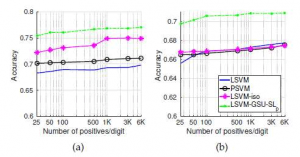
در دیتاست MNIST همانطور که مشخص است نمودار SVM GSU میزان دقت بالاتری نسبت به دیگر روش ها دارد.
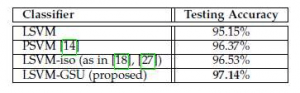
در دیتاست WDBC حدود ۲ درصد روش پیشنهادی این مقاله دقت بالاتری نسبت به سایر روش ها دارد.
کارهای آینده
در این مقاله ذکر نشده است ولی میتوان این روش را برای مسائل غیرخطی به کار برد و حتی توزیع های آماری دیگری را مورد بررسی قرار داد.
نقاط قوت
از جهت ایده:
.۱٫تمرکز بر داده های غیرمطمین که یکی از چالش های مهم هوش مصنوعی است.
.۲٫استفاده از الگوریتم ماشین بردار پشتیبان که یکی از بهترین طبقه بندهای موجود است.
.۳٫در مسائل طبقه بندی خطی میشود از این روش استفاده کرد بدلیل بهبود بخشیدن دقت کلاسیفایر
از جهت ارزیابی:
.۱٫استفاده از دیتاست های استاندارد و قابل دسترسی برای عموم یک مزیت عمده است. زیرا محققان دیگر نیز می توانند روش خود را با این روش مقایسه کنند.
نقاط ضعف
.۱٫در خصوص انتخاب توزیع گوسی دلیل مشخصی وجود ندارد و آیا میشود از توزیع های آماری دیگری استفاده کرد یا خیر.
.۲٫در خصوص نقاط قوت و ضعف این توزیع هیچ اثباتی صورت نگرفته است.
دانشگاه آزاد اسلامی واحد تهران شمال
موضوع : گزارش تحقیقاتی
گرداورنده: مائده اسماعیلی همدانی
استاد محترم : دکتر منثوری
نام ژورنال: پراسیدینگ IEEEدر موضوع تحلیل الگو و هوش ماشینی
سال انتشار : ۲۰۱۷
نویسندگان : کریستوز تزلپیس، دانشجوی عضو ،IEEEواسیلیوز مزاریس، عضو ارشد
IEEEو لونیس پاتراس، عضو ارشد IEEE





