



A Meta-Cognitive Learning Algorithm for an Extreme Learning Machine Classifier
.۱٫بیان مساله: این مقاله چه مساله ای را حل می کند؟
این مقاله یک طبقه بند یادگیری سریع موثر را مبتنی بر مدل Nelson و Naren از یادگیری شناختی متا به نام ماشین یادگیری شناختی متا معرفی می کند. MCELM دارای دو جز است: یکی جز شناختی و یک جز شناختی متا.
جز شناختی MCELM یک طبقه بند یادگیری بی نهایت سه لایه ای است. نورون ها در لایه پنهان از اجزای شناختی، تابع فعال گوسین را بکار می برند، در حالی که نورون ها در لایه ورودی و خروجی خطی هستند. اجزای شناختی متا از MCELM دارای مکانیسم یادگیری خود تنظیمی هستند که تصمیم می گیرد که چه چیز و چه زمان و چگونه یادگیری انجام شود. همانطور که نمونه ها در مجموعه آموزش یکی یکی ارائه می شود، اجزای شناختی متا سیگنال های نظارتی را از اجزای شناختی دریافت کرده و استراتژی یادگیری مناسب را برای نمونه انتخاب می کند. سپس این نمونه ها را حذف کرده و از نمونه هایی جهت اضافه کردن یک نورون جدید استفاده می کند و وزن های خروجی را مبتنی بر نمونه به روز رسانی می کند و یا نمونه را برای استفاده های بعدی ذخیره می کند. بنابراین متفاوت از ، ELM ساختار MCELM شبکه ای است که در طول پروسه آموزش ساخته می شود. در زمانی که یک نورون اضافه می شود، MCLEMیک مرکزی را مبتنی بر نمونه و عرض تابع گوسی به صورت تصادفی انتخاب می کند. وزن های خروجی با استفاده از حداقل مربعات تخمین زده شده که مبتنی بر تابع خطای hing-loss است، پیش بینی بهتری از احتمال پسین نسبت به میانگین مربعات خطا دارد. در حالی که پارامترهای شبکه به روز رسانی می شود، وزن های خروجی با استفاده از تخمین حداقل مربعات بازگشتی به روز رسانی می شود.عملکرد MCELM بر روی مجموعه ای از مسائل طبقه بندی از ماشین یادگیری UCI ارزیابی شد. مطالعات عملکردی نشان داد که ساختار شناختی متا در ELM نسبت به ELM دارای قدرت تصمیم گیری بهتری است.
.۲٫فرضیات مساله: برای حل مساله چه فرضیاتی در نظر گرفته شده است؟
.۱الگوریتم یادگیری شناختی متا برای طبقه بند ELM موثر و دقیق است.
MCELM .2 به بهبود توانایی تعمیم پذیری ELM شناختی کمک می کند.
.۳٫راه حل های قبلی: روش های دیگران برای حل این مساله چه چیزهایی بوده است؟
به تازگی، در مقالات قبلی روش های یادگیری نشان داده شده است که یادگیری خودتنظیمی که قادر به ارزیابی چیزی است که باید یاد بگیرد و چگونگی یادگیری بهترین استراتژی یادگیری معرفی شده است. الگوریتم های فوق الذکر فقط به نحوه یادگیری اشاره دارند و توانایی ارزیابی خود را در مجموعه داده های آموزشی ندارند. شناخت متا، انسان را قادر می سازد تا توانایی های دانش خود را ارزیابی کند و به یادگیری خود تنظیمی در یک فرد کمک کند. همانطور که تمام الگوریتم های یادگیری ماشین در دسترس در گذشته از اصول یادگیری انسان الهام می گیرند. گسترش اصول خود تنظیمی در چارچوب شناختی متا یک جنبه مهم برای توسعه الگوریتم های یادگیری ماشین کارآمد است. اخیرا، یک کلاس از الگوریتم های یادگیری شناختی متا بر اساس مدل ساده نلسون و Narens از شناخت متا انسان ساخته شده است. این الگوریتم های یادگیری پیوسته به ساختار شبکه نیاز ندارد که به طور پیش فرض ثابت شود. آنها در طول فرآیند آموزش، شبکه را با افزودن نورون ها و یا به روز رسانی پارامترهای شبکه با استفاده از فیلتر Kalman گسترش می دهند. برخی از الگوریتم های یادگیری ترتیبی موجود در گذشته عبارتند از: جمع آوری منابع شبکه، حداقل تخصیص منابع شبکه شبکه RBF رو به رشد، طبقه بندی تابع شعاعی چند دسته ای پیوسته، شبکه تخصیص منابع تطبیقی متوالی و شبکه عصبی متا.
.۴٫نوآوری: نوآوری این مقاله چیست؟
استفاده ز مدل NELSON و NAREN به عنوان یکی مدل ساده و توانا استفاده شده است. به دنبال این مدل ساده از شناخت متا، چندین الگوریتم یادگیری ماشین شناختی متا برای شبکه های عصبی با مقادیر واقعی و شبکه های عصبی با مقادیر پیچیده و سیستم ارتباط نروفازی معرفی شده است . SRAN اولین الگوریتم یادگیری متوالی خود تنظیمی برای شبکه عصبی RBF با مقدار واقعی است که در این مقاله استفاده شده است.
.۵٫راه حل پیشنهادی: قسمت های مختلف راه حل پیشنهادی و کاربرد هریک چیست ؟
این مقاله یک طبقه بند یادگیری سریع موثر را مبتنی بر مدل Nelson و Naren از یادگیری شناختی متا به نام ماشین یادگیری شناختی متا معرفی می کند . MCELM دارای دو جز است: یکی جز شناختی و یک جز شناختی متا. همانطور که نمونه ها در مجموعه آموزش یکی یکی ارائه می شود، اجزای شناختی متا سیگنال های نظارتی را از اجزای شناختی دریافت کرده و استراتژی یادگیری مناسب را برای نمونه انتخاب می کند. سپس این نمونه ها را حذف کرده و از نمونه هایی جهت اضافه کردن یک نورون جدید استفاده می کند و وزن های خروجی را مبتنی بر نمونه به روز رسانی می کند و یا نمونه را برای استفاده های بعدی ذخیره می کند. بنابراین متفاوت از ، ELM ساختار MCELM شبکه ای است که در طول پروسه آموزش ساخته می شود. در زمانی که یک نورون اضافه می شود، MCLEM یک مرکزی را مبتنی بر نمونه و عرض تابع گوسی به صورت تصادفی انتخاب می کند. وزن های خروجی با استفاده از حداقل مربعات تخمین زده شده که مبتنی بر تابع خطای hing-loss است، پیش بینی بهتری از احتمال پسین نسبت به میانگین مربعات خطا دارد. در حالی که پارامترهای شبکه به روز رسانی می شود، وزن های خروجی با استفاده از تخمین حداقل مربعات بازگشتی به روز رسانی می شود.عملکرد MCELM بر روی مجموعه ای از مسائل طبقه بندی از ماشین یادگیری UCI ارزیابی شد. در واقع در این مقاله از روش SRAN به عنوان اولین الگوریتم یادگیری متوالی خود تنظیمی استفاده شده که تصمیم می گیرد چه چیزی در چه زمان و چگونه یادگیری شود. کاربرد روش پیشنهادی در زمینه طبقه بندی یادگیری ماشین است.
.۶٫ارزیابی: راه حل پیشنهادی روی چه داده هایی پیاده سازی شدند؟
در کل Nنمونه آموزش وجود دارد که در آن X ویژگی های ورودی با مقدار واقعی M بعدی و T مشاهدات و C لیبل کلاس است. لیبل کلاس Y با رابطه زیر مشخص می شود:
![]()
برای ارزیابی معبار بدست آوردن ماکزیمم خطای hing-loss است که به صورت زیر محاسبه می شود:
![]()
و میزان ماکزیمم متوسط خطا به صورت زیر محاسبه می شود:
![]()
در جدول زیر اطلاعات درباره تعداد نمونه های آموزش و تست و تعداد ویژگی ها و تعداد کلاس های مورد نظر آمده است.
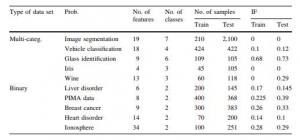
در این مقاله از داده های بخش بندی شده تصویر، طبقه بندی وسایل نقلیه، شناسایی لیوان و گل زنبق و بیماری های کلیه و داده PIMA و سرطان سینه و بیماری قلبی و (Ionosphere کره فضای یونی) استفاده گردید و نتایج به صورت مجزا بر روی هر داده بدست آمد. از دیگر معیارهای ارزیابی عملکرد می توان به موارد زیر اشاره کرد:
.۱٫میانگین بازدهی طبقه بندی: میانگین کارایی طبقه بندی (ga) به عنوان میانگین نسبت تعداد نمونه های صحیح طبقه بندی شده در هر کلاس به تعداد کل نمونه ها در هر کلاس تعریف می شود.
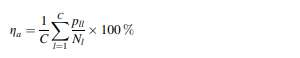
که در آن Pu تعداد کل نمونه هایی است که به درستی طبقه بندی شده در مجموعه داده های تست و آموزش بازده کل طبقه بندی: بازده طبقه بندی کل به عنوان نسبت تعداد کل نمونه های صحیح طبقه بندی شده به تعداد کل نمونه هایی که در مجموعه داده های آموزش / آزمایش وجود دارد، تعریف می شود.
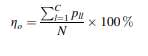
تعداد کلاس ها، تعداد نمونه های مورد استفاده در آموزش و تست و ضریب عدم تعادل (IF) مجموعه داده های مورد استفاده در عملکرد مطالعه بررسی شدند زیرا ممکن است بر عملکرد طبقه بندی طبقه بندی تاثیر بگذارد. برای بررسی تأثیر این عوامل، ضریب IF همچنین در مورد مجموعه داده های آموزشی و تست، که به شرح زیر تعریف می شود، در نظر گرفته شده است:
![]()
.۷٫نتایج: نتایج این شبیه سازی چگونه بوده است؟
نتایج نشان داد که وزن های خروجی با استفاده از حداقل مربعات تخمین زده شده که مبتنی بر تابع خطای
hing-loss است، پیش بینی بهتری از احتمال پسین نسبت به میانگین مربعات خطا دارد. در حالی که پارامترهای شبکه به روز رسانی می شود، وزن های خروجی با استفاده از تخمین حداقل مربعات بازگشتی به روز رسانی می شود. عملکرد MCELM بر روی مجموعه ای از مسائل طبقه بندی از ماشین یادگیری UCI ارزیابی شد. مطالعات عملکردی نشان داد که ساختار شناختی متا در ELM نسبت به ELM دارای قدرت تصمیم گیری بهتری است. هم چنین جهت ارزیابی عملکرد پارمترهای ذکر شده در بخش قبلی مانند ضریب IF و میانگین بازدهی طبقه بندی و بازده کل طبقه بندی بدست آمد که در جدول های زیر نشان داده شده است. مقادیر میانگین بازدهی طبقه بندی و بازده کل طبقه بندی برای همه داده ها
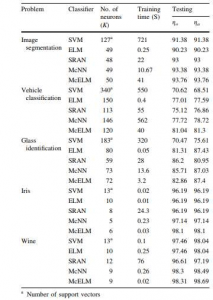
نتایج نشان داد که مقادیر هر دو بازده برای MCNN و MCELM برای تمام داده ها به خصوص wine بیش تر است.
نتایج ضریب F1
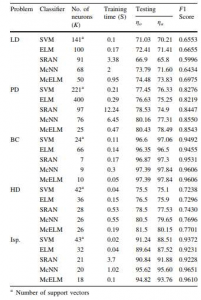
نتایج نشان داد که مقادیر ضریب F1 برای MCNN و MCELM برای تمام داده ها به خصوص wine بیش تر است.
.۸٫کارهای آینده: آیا مقاله پیشنهادی برای ادامه کار داشته است؟ اگر نداشته پیشنهاد شما چیست؟
توسعه الگوریتم استفاده شده در این مقاله بر روی مجموعه داده های بیش تر و دیگر مجموعه داده ها
.۸٫۱٫نقاط قوت: از دیدگاه شما نقاط قوت این مقاله چیست؟
الگوریتم های قبلی فقط به نحوه یادگیری اشاره دارند و توانایی ارزیابی خود را در مجموعه داده های آموزشی ندارند. شناخت متا، انسان را قادر می سازد تا توانایی های دانش خود را ارزیابی کند و به یادگیری خود تنظیمی در یک فرد کمک کند. همانطور که تمام الگوریتم های یادگیری ماشین در دسترس در گذشته از اصول یادگیری انسان الهام می گیرند. گسترش اصول خود تنظیمی در چارچوب شناختی متا یک جنبه مهم برای توسعه الگوریتم های یادگیری ماشین کارآمد است. هم چنین شبکه ELM یک الگوریتم یادگیری سریع است، لازم است که اصول شناخت متا را به ELM گسترش دهد، به طوری که الگوریتم یادگیری سریع متا توسعه یابد. بنابراین در این مقاله یک الگوریتم یادگیری متا برای یک طبقه بندی ELM با یک تابع فعال q-Gauss در لایه پنهان ایجاد گردیده است. نتایج حاصل بر روی دسته داده های مختلف نشان داد که MCELMدارای توانایی تعمیم پذیری بالایی است و هم چنین از نظر محاسباتی دارای پیچیدگی نسبت به SRAN و MCNN نمی باشد. بنابراین، از مطالعه عملکردی در مورد مسائل طبقه بندی متفاوت، می توان نتیجه گرفت که McELM از الگوریتم های موجود در مقالات قبلی بهتر عمل می کند و شناخت متا به بهبود توانایی تعمیم
ELM کمک می کند.
.۸٫۲٫نقاط ضعف: از دیدگاه شما نقاط قوت این مقاله چیست؟
این مقاله از نقطه نظر تعمیم پذیری و محاسبات کم تر و درصدهای ضریب F1 و بازدهی دارای نقطه ضعفی نمی باشد. هم چنین بر روی مجموعه داده های بیشتر اجرا شده که نشان دهنده قدرت تعمیم پذیری بالای الگوریتم است.





