



Learning Word Vectors for Sentiment
Analysis
بیان مسئله:
متدهای معناشناختی بردار مبنای بدون نظارت می توانند معناهای لغوی غنی را مدلسازی کنند، اما در بدست آوردن اطلاعات احساسی که برای بسیاری از کلمات اساسی و برای بازه وسیعی از کاربردهای NLP حائز اهمیت است کاملا ناموفق می باشند. نمایش های کلمات جزئی اساسی از بسیاری از سیستم های پردازش زبان طبیعی می باشند. نمایش کلمات به صورت اندیس در فرهنگ لغات مرسوم است، اما این کار در ثبت ساختار ارتباطی غنی واژگانی ناموفق است.
ما مدلی ارائه می کنیم که از ترکیبی از روش های بدون نظارت و با نظارت برای یاد دادن درک اصطلاحات احساسی با بردارهای کلمات – هم اطلاعات مستند و هم محتوای احساسی غنی استفاده می کند. مدل ارائه شده می تواند هم از اطلاعات احساسی پیوسته و چند بعدی و هم از تفسیرهای غیر احساسی بهره ببرد. ما این مدل را با بکارگیری تفسیرهای قطبی احساسی سطح متون که در بسیاری متون آنلاین (مثل رتبه بندی های ستاره ای) وجود دارند امتحان می کنیم. ما این مدل را با استفاده از مجموعه نوشتجات کوچک و پر استفاده احساسی و ذهنیتی ارزیابی کرده و متوجه شدیم که نسبت به تعدادی از روش های پیشین معرفی شده برای طبقه بندی احساسی برتر بود. همچنین یک مجموعه داده بزرگ از نقد فیلم ها به عنوان معیاری محکم تر در این زمینه معرفی می کنیم.
فرضیات مسئله:
ما یک مدل فضا برداری ارائه کردیم که با ضبط اطلاعات معنایی و احساسی، نمایش های کلمات را یاد می گیرد. اساس احتمالاتی این مدل یک تکنیک از نظر تئوری موجه برای مقایسه بردار کلمات به عنوان جایگزینی برای تکنیک های ماتریسی مبتنی بر عامل بندی بسیاری که معمولا استفاده می شوند ارائه می دهد. مدل ما با پیروی از موفقیت های اخیر در استفاده از تکنیک های مشابه برای مدل های زبان به عنوان یک مدل لگاریتم دو سویه پارامتری سازی می شود و با مدل های موضوع پنهان احتمالاتی مرتبط است. ما جزء موضوعی مدل خود را به شیوه ای پارامتری سازی کردیم که بجای موضوعات پنهان، نمایش های کلمات را ثبت می کند. در آزمایش ها، مدل ما از LDA، که به صورت مستقیم موضوعات پنهان را مدلسازی می کند، بهتر عمل کرد
راه حل های قبلی:
مدلی که در بخش بعد معرفی می کنیم از کارهای قبلی روی مدلسازی موضوعی احتمالی و مدل های بردار فضایی برای معنای کلمات الهام گرفته است. تخصیص پنهان دیریکله (LDAY؛ بلی و همکاران ۲۰۰۳) یک مدل متن احتمالی است که فرض می کند هر متن ترکیبی از موضوعات پنهان است. برای هر موضوع پنهان T، این مدل یک توزیع شرطی p(w|T) برای احتمال اینکه کلمه w در T اتفاق می افتد یاد می گیرد. می توان با آموزش یک مدل k موضوعی و پر کردن ماتریس با مقادیر p(w|T) (استاندارد شده با طول واحد) یک نمایش برداری k بعدی از کلمات بدست آورد. حاصل یک ماتریس کلمه-موضوع خواهد بود که در آن ردیف ها نماینده ی معنای کلمات می باشند. اگرچه، به دلیل اینکه تاکید LDA روی مدلسازی موضوعات است، نه معنای کلمات، هیچ تضمینی وجود ندارد که بردارهای ردیفی (کلمه) به صورت نقاطی در یک فضای k بعدی مشهود باشند. در واقع، در بخش ۴ نشان می دهیم که استفاده از LDA به این روش بردارهای کلمات خوبی ارائه نمی کند. جزء معنایی مدل ما پایه مشترکی با LDA دارد، اما طوری ضریب گذاری شده است تا بجای موضوعات پنهان بردارهای کلمات را پیدا کند. برخی از کارهای اخیر تعمیم هایی از LDA معرفی کرده اند که علاوه بر اطلاعات موضوعی، احساسات را نیز ثبت می کنند (لی و همکاران ۲۰۱۰؛ لین و هه ۲۰۰۹؛ بوید گرابر و رسنیک ۲۰۱۰). همانند LDA، تمرکز این روش ها به جای بازنمایی لغات (word embedding) در یک فضای برداری، بر روی مدلسازی موضوعات احساساتی است.
مدل های فضای برداری (VSM ها) سعی می کنند کلمات را مستقیما مدلسازی کنند (تورنی و پانتل ۲۰۱۰). تحلیل معنایی پنهان (LSA)، که شاید شناخته شده ترین VSM باشد، آشکارا با انجام تجزیه مقدارهای منفرد (SVD) برای بخش کردن یک ماتریس وقوع همزمان اصطلاح-متن بردارهای کلمات معنایی را یاد می گیرد. وزن دهی و استانداردسازی مقادیر ماتریس قبل از SVD مرسوم است. برای دستیابی به یک نمایس k بعدی از یک کلمه معین، تنها ورودی هایی که با بزرگترین مقادیر منفرد k مطابقت دارند از مبنای کلمه در ماتریس ضریب دهی شده برداشته می شوند. چنین متدهایی که مبتنی بر ضریب دهی ماتریس می باشند در عمل بسیار موفق هستند، اما محقق را مجبور می سازند که با راهنمایی تئوری اندکی در مورد انتخاب ارجح، انتخاب های طراحی زیادی (وزن دهی، استانداردسازی، الگوریتم کاهش ابعاد) انجام دهد.
استفاده از وزن دهی تکرار اصطلاح (tf) و تکرار متن معکوس (idf) برای تبدیل مقادیر در یک VSM معمولا عملکرد سیستم های بازیابی و طبقه بندی را بالا می برد. وزن دهی idf دلتا (مارتینیو و فینین ۲۰۰۹) یک متغیر با نظارت از وزن دهی idf است که در آن محاسبه idf برای هر کلاس متنی انجام شده و سپس یک مقدار از مقدار دیگر کسر می شود. مارتینیو و فینین شواهدی ارائه می دهند که این وزن دهی به طبقه بندی احساسی کمک می کند، و پالتاگلو و دلوال (۲۰۱۰) به صورت سیستماتیک تعدادی طرح وزن دهی را در زمینه تحلیل احساسات بررسی می کنند. موفقیت وزن دهی idf در کارهای قبلی اذعان می دارد که جای دادن اطلاعات احساسی در مقادیر VSM از طریق روش های با نظارت برای تحلیل احساسات مفید است. ما این مسئله را در مدل خود در نظر گرفتیم، اما همچنین قادر خواهیم بود آن را به صورت مستقیم در تابع هدف مدل خود بگنجانیم
نو آوری:
در این مقاله، مدلی برای ثبت و شناسایی شباهت های معنایی و احساسی میان کلمات ارائه می دهیم. جزء معنایی مدل ما بردارهای کلمات را از طریق یک مدل احتمالی بدون نظارت از متون یاد می گیرد. اگرچه، بر طبق پژوهش های زبان شناسی و شناختی که استدلال می کنند محتوای بیانی و محتوای معنایی توصیفی از هم جدا می باشند، ما دریافتیم که این مدل بنیادی اطلاعات احساسی مهمی را کم دارد. برای مثال، با وجود اینکه این مدل یاد می گیرد که شگفت انگیز (wonderful) و متحیر کننده (amazing) از نظر معنایی نزدیک اند، متوجه نمی شود که این دو لغت در واقع کلماتی از نظر احساسی بسیار مثبت می باشند که در آن سوی طیف وحشتناک (terrible) و افتضاح (awful) قرار می گیرند.
بنابراین، ما این مدل را با یک جزء احساسی با نظارت که قادر است بسیاری از جنبه های اجتماعی و نگرشی معنا را شامل شود تعمیم دادیم. این جزء مدل از نمایش برداری کلمات برای پیش بینی تفسیرهای احساسی متونی که این کلمات در آنها ظاهر می شوند استفاده می کند. این امر باعث می شود کلماتی که احساس مشابهی را بیان می کنند نمایش های برداری مشابهی داشته باشند. در نتیجه، تابع هدف کامل این مدل بردارهای معنایی را که با اطلاعات معنایی منحصربفرد آمیخته شده اند یاد می گیرد. در آزمایش ها نشان می دهیم که چطور این مدل می تواند از تفسیرهای احساسی سطح متنی که به شکل نقد فیلم ها، محصولات و غیره به صورت آنلاین به وفور یافت می شوند بهره ببرد. این تکنیک به خوبی می تواند با مفاهیم پیوسته و چند بعدی احساسی و همچنین تفسیرهای غیر احساسی (مثل وابستگی سیاسی، وفاداری سخنگو) کار کند.
راه حل پیشنهادی:
به منظور ثبت شباهت های معنایی در میان کلمات، ما یک مدل احتمالی از متون بدست آوردیم که نمایش های کلمات را یاد می گیرد. این جزء نیازمند داده های برچسب گذاری شده نبوده و پایه مشترکی با مدل های موضوعی احتمالی مثل LDA دارد. جزء احساسی مدل ما از تفسیرهای احساسی استفاده می کند تا کلماتی که احساسات مشابهی بیان می کنند را طوری مقید کند که نمایش های مشابهی داشته باشند. این مدل می تواند با استفاده از حداکثرسازی تناوبی به خوبی پارامترهای تابع هدف مشترک را فرا گیرد.
۱٫ثبت شباهت های معنایی:
ما با استفاده از یک توزیع مرکب پیوسته از کلمات شاخص گذاری شده توسط یک متغیر چند بعدی تصادفی θ یک مدل احتمالی از متون ساختیم. فرض می کنیم که کلمات درون یک متن با توجه به متغیر مرکب θ به صورت مشروط مستقل اند. با استفاده از یک توزیع مشترک بین متن و θ یک احتمال به متن d تخصیص می دهیم. مدل هر کلمه wi ∈ d را به صورت مشروط مستقل از دیگر کلمات θ معین فرض می کند. در نتیجه احتمال متن می شود:
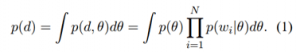 به طوریکه N تعداد کلمات در d و wi کلمه i ام در d است. ما از یک توزیع گاوسی پیشین روی θ استفاده کردیم. ما توزیع شرطی p(wi|θ) را با استفاده از یک مدل لگاریتم خطی با پارامترهای R و b تعریف کردیم. تابع انرژی از یک ماتریس نمایش کلمات R ∈ ℝ(β × |V|) استفاده می کند که در آن هر کلمه w (نمایش به صورت یک بردار (one-on) در لغت نامه V یک نمایش برداری β بعدی Φw = Rw دارد که با ستون آن کلمه در R مطابقت دارد. متغیر تصادفی θ نیز یک بردار β است، θ ∈ ℝβ که به اندازه هر کدام از β بعد بردارهای نمایش کلمات وزن می گیرد. ما همچنین یک پیشقدر bw نیز برای هر کلمه معرفی می کنیم تا تفاوت های موجود در کل تکرارهای کلمه ثبت شود. انرژی تخصیص داده شده به یک کلمه w با توجه به این پارامترهای مدل عبارت است از:
به طوریکه N تعداد کلمات در d و wi کلمه i ام در d است. ما از یک توزیع گاوسی پیشین روی θ استفاده کردیم. ما توزیع شرطی p(wi|θ) را با استفاده از یک مدل لگاریتم خطی با پارامترهای R و b تعریف کردیم. تابع انرژی از یک ماتریس نمایش کلمات R ∈ ℝ(β × |V|) استفاده می کند که در آن هر کلمه w (نمایش به صورت یک بردار (one-on) در لغت نامه V یک نمایش برداری β بعدی Φw = Rw دارد که با ستون آن کلمه در R مطابقت دارد. متغیر تصادفی θ نیز یک بردار β است، θ ∈ ℝβ که به اندازه هر کدام از β بعد بردارهای نمایش کلمات وزن می گیرد. ما همچنین یک پیشقدر bw نیز برای هر کلمه معرفی می کنیم تا تفاوت های موجود در کل تکرارهای کلمه ثبت شود. انرژی تخصیص داده شده به یک کلمه w با توجه به این پارامترهای مدل عبارت است از: ![]()
برای بدست آوردن توزیع p(w|θ)، از یک softmax استفاده می کنیم:
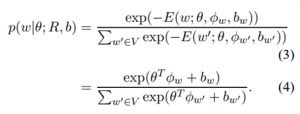
تعداد اصطلاحات موجود در مجموع مخرج به صورت خطی با |V| افزایش یافته و محاسبه دقیق توزیع را ممکن می سازد. برای یک θ معین، احتمال وقوع کلمه w با مقدار انطباق بردار نمایش آن Φw با جهت بزرگ شدن θ مرتبط است. این نظریه شبیه به محصول داخلی بردار کلمه به کار رفته در مدل زبان لگاریتم دو خطی منی و هینتون (۲۰۰۷) می باشد. معادله ۱ شبیه مدل احتمال LDA است که متون را به صورت ترکیبی از موضوعات پنهان مدلسازی می کند. می توان ورودی های یک بردار کلمه Φ را به صورت قدرت مشارکت کلمه نسبت به هر بعد موضوع پنهان در نظر گرفت. بنابراین، متغیر تصادفی θ وزن موضوعات را تعیین می کند. اگرچه، هدف مدل ما مدلسازی موضوعات مستقل نیست، بلکه این مدل به صورت مستقیم شرایط احتمال وقوع کلمه در متغیر مرکب موضوعی θ را مدلسازی می کند. به دلیل فرمولاسیون لگاریتم خطی توزیع مشروط، θ برداری در ℝβ بوده و همانند LDA محدود به کلمه ساده واحد (unit simplex) نیست. اکنون حداکثر احتمال یادگیری این مدل برای مجموعه معینی از متون برچسب گذاری نشده D را بدست می آوریم. در حداکثر احتمال یادگیری، ما احتمال مشاهده داده را با توجه به پارامترهای مدل بیشینه می کنیم. فرض می کنیم که متون dk ∈ D نمونه های i.i.d می باشند. در نتیجه، مسئله یادگیری عبارت خواهد بود از: 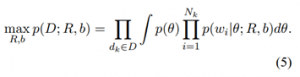
با استفاده از تخمین بیشینه گر احتمال پسین (MAP) برای θ مسئله یادگیری را به صورت زیر تقریب می زنیم:
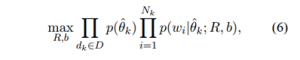
به طوریکه θ̂k نشانگر تخمین MAP θ برای dk می باشد. ما یک عبارت تصحیح نرمال (norm regularization term) فروبنیوس برای ماتریس نمایش کلمه R معرفی می کنیم. پیشقدرهای کلمه b تصحیح نمی شوند تا اجازه دهیم پیشقدرها آمار کلی تکرار کلمه موجود در داده ها را بدست آورند. با لگاریتم گیری و ساده سازی هدف نهایی را بدست می آوریم:
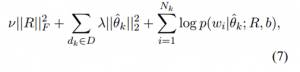
که نسبت به R و b بیشینه می شود. هایپر پارامترهای موجود در مدل عبارت اند از وزن های تصحیحی (λ و ν) و ابعاد بردار کلمه β.
۲٫ثبت احساسات کلمه:
مدل ارائه شده تا اینجا به صورت آشکار اطلاعات احساسی را ثبت نمی کند. اعمال این الگوریتم بر متون نمایش هایی تولید خواهد کرد که در آنها کلماتی که با هم در متون می آیند نمایش های مشابهی دارند. هرچند، این متد بدون نظارت بر عکس متدهای مرتبط با محتوا هیچ شیوه آشکاری از ثبت اینکه کدام کلمات پیش بینی کننده احساسات هستند ندارند. کارهای قبلی در زمینه پردازش زبان طبیعی با یادگیری از چندین تمرین نمایش های بهتری بدست می آورند .در همین راستا، ما یک تمرین دیگر برای به کارگیری متون برچسب گذاری شده به منظور بهبود نمایش های کلمات مدل خود معرفی می کنیم.احساس یک مفهوم پیچیده چند بعدی است. بسته اینکه کدام یک از جنبه های احساسات را می خواهیم ثبت کنیم، می توانیم یک برچسب احساسی به بخشی از یک متن بدهیم که می تواند قطعی (categorical)، پیوسته (continuous)، یا چند بعدی باشد. به منظور بهره بردن از چنین برچسب هایی، این هدف را معرفی می کنیم که بردارهای کلمات مدل ما باید با استفاده از پیشگویی های مناسب برچسب احساس را پیش بینی کند.
 با استفاده از یک تابع پیشگویی مناسب f(x) یک بردار کلمه Φw را به یک برچسب احساس پیش بینی شده Ŝ مپ می کنیم. سپس می توانیم بردار کلمه Φw خود را طوری بهبود دهیم که برچسب های احساسی متونی که آن کلمه در آنها حضور دارد را بهتر پیش بینی کند. برای سادگی کار، مثالی را در نظر می گیریم که در آن برچسب احساس s یک مقدار پیوسته عددی (scalar) است که قطبیت احساسی متن را نمایش می دهد. این مثال در بسیاری از نقدهای آنلاین که در آنها متون با یک رده بندی ستاره ای برچسب گذاری می شوند قابل مشاهده است. ما چنین مقادیر ستاره ای را به صورت خطی با فواصل s ∈ [۰,۱] مپ کرده و آنها را به عنوان احتمال قطبیت احساس مثبت در نظر می گیریم. با استفاده از این فرمولاسیون، یک رگرسیون لاجستیک را به عنوان تابع پیشگوی f(x) به کار می گیریم. سپس از نمایش برداری w، Φw، و وزن های رگرسیون ψ برای بیان آن به صورت زیر استفاده می کنیم:
با استفاده از یک تابع پیشگویی مناسب f(x) یک بردار کلمه Φw را به یک برچسب احساس پیش بینی شده Ŝ مپ می کنیم. سپس می توانیم بردار کلمه Φw خود را طوری بهبود دهیم که برچسب های احساسی متونی که آن کلمه در آنها حضور دارد را بهتر پیش بینی کند. برای سادگی کار، مثالی را در نظر می گیریم که در آن برچسب احساس s یک مقدار پیوسته عددی (scalar) است که قطبیت احساسی متن را نمایش می دهد. این مثال در بسیاری از نقدهای آنلاین که در آنها متون با یک رده بندی ستاره ای برچسب گذاری می شوند قابل مشاهده است. ما چنین مقادیر ستاره ای را به صورت خطی با فواصل s ∈ [۰,۱] مپ کرده و آنها را به عنوان احتمال قطبیت احساس مثبت در نظر می گیریم. با استفاده از این فرمولاسیون، یک رگرسیون لاجستیک را به عنوان تابع پیشگوی f(x) به کار می گیریم. سپس از نمایش برداری w، Φw، و وزن های رگرسیون ψ برای بیان آن به صورت زیر استفاده می کنیم: ![]() به طوری که σ(x) تابع لاجستیک و ψ ∈ ℝβ بردار وزنی رگرسیون لاجستیک است. همچنین یک پیشقدر عددی bc نیز برای طبقه بندی کننده تعریف می کنیم. وزن های رگرسیون لاجستیک ψ و bc یک ابر صفحه (hyperplane) خطی در فضای برداری کلمه تعریف می کنند که در آن احتمال احساس مثبت بردار کلمه به این بستگی دارد که نسبت به این ابر صفحه در کجا قرار می گیرد. یادگیری در مجموعه ای از این متون منجر به این شد که کلمات بر اساس قطبیت متوسط متونی که در آنها ظاهر می شوند در فواصل مختلفی از این ابر صفحه قرار می گیرند. با در نظر گرفتن مجموعه ای از متون برچسب گذاری شده D که در آن sk برچسب احساس متن dk است، قصد داریم که احتمال برچسب های متون این مجموعه را بیشینه سازیم. فرض می کنیم که متون این مجموعه و کلمات درون متون نمونه های i.i.d می باشند. با بیشینه ساختن لگاریتم – هدف خواهیم داشت،
به طوری که σ(x) تابع لاجستیک و ψ ∈ ℝβ بردار وزنی رگرسیون لاجستیک است. همچنین یک پیشقدر عددی bc نیز برای طبقه بندی کننده تعریف می کنیم. وزن های رگرسیون لاجستیک ψ و bc یک ابر صفحه (hyperplane) خطی در فضای برداری کلمه تعریف می کنند که در آن احتمال احساس مثبت بردار کلمه به این بستگی دارد که نسبت به این ابر صفحه در کجا قرار می گیرد. یادگیری در مجموعه ای از این متون منجر به این شد که کلمات بر اساس قطبیت متوسط متونی که در آنها ظاهر می شوند در فواصل مختلفی از این ابر صفحه قرار می گیرند. با در نظر گرفتن مجموعه ای از متون برچسب گذاری شده D که در آن sk برچسب احساس متن dk است، قصد داریم که احتمال برچسب های متون این مجموعه را بیشینه سازیم. فرض می کنیم که متون این مجموعه و کلمات درون متون نمونه های i.i.d می باشند. با بیشینه ساختن لگاریتم – هدف خواهیم داشت،  احتمال شرطی p(sk|wi;R,ψ,bc) به راحتی از معادله ۹ بدست می آید.
احتمال شرطی p(sk|wi;R,ψ,bc) به راحتی از معادله ۹ بدست می آید.
۳٫یادگیری:
هدف یادگیری کامل مجموعی از دو هدف ارائه شده را بیشینه می سازد. این امر یک تابع هدف نهایی به صورت زیر تولید می کند، 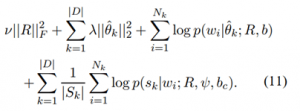 |Sk| نشان دهنده تعداد متون در مجموعه داده است که مقدار گرد شده sk یکسانی دارند (یعنی، sk<0.5 و sk≥۰٫۵). برای جبران عدم توازن مشهود در رده بندی های موجود در مجموعه نقدها وزن دهی را معرفی می کنیم. این وزن دهی از اینکه توزیع کلی رده های متون تخمین رده بندی متنی که یک کلمه مشخص در آن وجود دارد را تحت تاثیر قرار دهد جلوگیری می کند. هایپر پارامترهای این مدل وزن های رگولاریزاسیون (λ و ν)، و بعد بردار کلمه β می باشند. بیشینه سازی تابع هدف نسبت به R، b، ψ، و bc یک مسئله غیر محدب است. ما از بیشینه سازی متناوب استفاده می کنیم که ابتدا با ثابت نگه داشتن تخمین های MAP (θ̂) نمایش های کلمه (R، b، ψ، و bc) را بهینه می سازد. سپس با ثابت نگه داشتن نمایش های کلمات تخمین MAP جدید را برای هر متن بدست می آوریم و تا همگرایی کامل این کار را ادامه می دهیم. الگوریتم بهینه سازی به سرعت یک پاسخ جهانی برای هر θ̂k بدست می آورد چرا که برای هر θ̂k یک مسئله محدب با بعد پایین داریم. از آنجایی که مسائل تخمین MAP برای متون مختلف مستقل می باشند، می توانیم آنها را به صورت موازی روی ماشین های مختلف حل کنیم. این امر رده بندی مدل را در جمع آوری صدها هزار متن تسهیل می کند.
|Sk| نشان دهنده تعداد متون در مجموعه داده است که مقدار گرد شده sk یکسانی دارند (یعنی، sk<0.5 و sk≥۰٫۵). برای جبران عدم توازن مشهود در رده بندی های موجود در مجموعه نقدها وزن دهی را معرفی می کنیم. این وزن دهی از اینکه توزیع کلی رده های متون تخمین رده بندی متنی که یک کلمه مشخص در آن وجود دارد را تحت تاثیر قرار دهد جلوگیری می کند. هایپر پارامترهای این مدل وزن های رگولاریزاسیون (λ و ν)، و بعد بردار کلمه β می باشند. بیشینه سازی تابع هدف نسبت به R، b، ψ، و bc یک مسئله غیر محدب است. ما از بیشینه سازی متناوب استفاده می کنیم که ابتدا با ثابت نگه داشتن تخمین های MAP (θ̂) نمایش های کلمه (R، b، ψ، و bc) را بهینه می سازد. سپس با ثابت نگه داشتن نمایش های کلمات تخمین MAP جدید را برای هر متن بدست می آوریم و تا همگرایی کامل این کار را ادامه می دهیم. الگوریتم بهینه سازی به سرعت یک پاسخ جهانی برای هر θ̂k بدست می آورد چرا که برای هر θ̂k یک مسئله محدب با بعد پایین داریم. از آنجایی که مسائل تخمین MAP برای متون مختلف مستقل می باشند، می توانیم آنها را به صورت موازی روی ماشین های مختلف حل کنیم. این امر رده بندی مدل را در جمع آوری صدها هزار متن تسهیل می کند.
نقاط قوت و ضعف:
جدول ۲ دقت های طبقه بندی آزمایش ذهنیتی جمله را نشان می دهد. در اینجا نیز مدل ما در مقایسه با VSM های دیگر ویژگی های بهتری ارائه داده است. با ترکیب دو بردار ویژگی بهبودی در صندوقچه کلمات پایه مشاهده می شود.
ارزیابی:
ما مدل خود را با وظایف طبقه بندی در سطح متن و در سطح جمله در حوزه نقد فیلم های آنلاین ارزیابی می کنیم. برای طبقه بندی متون، ما مدل خود را با نتایج منتشر شده روی یک مجموعه داده استاندارد مقایسه کرده و یک مجموعه داده جدید برای این وظیفه معرفی می کنیم. در هر دو وظیفه، ما نمایش های کلمه مدل خود را با چندین روش وزن دهی صندوقچه کلمات (bag of words) و روش های دیگری برای استنتاج بردار کلمات مقایسه می کنیم.
۱-یادگیری نمایش کلمات:
ما نمایش های کلمات را با استفاده از ۲۵۰۰۰ نقد فیلم از IMDB با مدل خود استنتاج می کنیم. به دلیل اینکه برخی فیلم ها نقدهای بسیار بیشتری نسبت به دیگر فیلم ها می گیرند، ما داده ها را به حداکثر ۳۰ نقد از هر فیلم در مجموعه خود محدود کردیم. ما یک دیکشنری ثابت از ۵۰۰۰ از پر استفاده ترین توکن ها ایجاد کردیم اما ۵۰ تا از پر استفاده ترین اصطلاحات را از لغت نامه کامل اصلی حذف کردیم. روش مرسوم حذف ایست واژه ها (Stop Word) استفاده نشد چرا که ایست واژه های مشخصی (مثل کلمات نفی کننده) نشان دهنده احساسات هستند. روش قطع ریشه (stemming) نیز استفاده نشد چرا که این مدل نمایش های مشابه کلماتی از یک ریشه را در صورت اظهار داده ها یاد می گیرد. به علاوه، به دلیل اینکه توکن های غیر کلمه ای خاصی (مثل “!” و “:-)”) نشان دهنده احساس می باشند، آنها را نیز در لغت نامه خود جای داده ایم. رده بندی های IMDB به صورت مقادیر ستاره ای ارائه می شوند (∈ {۱,۲,…,۱۰}) که به صورت خطی با [۰,۱] مپ می شوند تا هنگام آموزش مدل به عنوان برچسب های متون استفاده شوند.
جزء معنایی مدل ما نیازمند برچسب متن نیست. ما یک نوع از مدل خود را که از ۵۰۰۰۰ نقد برچسب گذاری نشده به علاوه یک مجموعه ۲۵۰۰۰ نقدی برچسب گذاری شده استفاده می کند آموزش دادیم. مجموعه برچسب گذاری نشده نقدها شامل نقدهای خنثی و همچنین نقدهای قطبی شده شبیه به آنهایی که در مجموعه برچسب گذاری شده نیز یافت می شوند می باشد. آموزش مدل با داده های برچسب گذاری نشده اضافی یک سناریوی مشترک بدست می آورد که در آن تعداد داده های برچسب گذاری شده نسبت به تعداد داده های برچسب گذاری نشده موجود کمتر است. برای تمامی مدل های بردار کلمات، از بردارهای ۵۰ بعدی استفاده می کنیم. به عنوان یک ارزیابی کیفی از نمایش های کلمات، ما با استفاده از شباهت برداری نمایش های یاد گرفته شده شبیه ترین کلمات به کلمه مورد جستجو را مجسم می کنیم. با در نظر گرفتن کلمه مورد جستجوی w و کلمه دیگر w’، نمایش های برداری آنها Φw و Φw’ را بدست آورده و شباهت کسینوسی آنها را به صورت ارزیابی می کنیم. با ارزیابی شباهت w با تمامی دیگر کلمات w’، می توانیم کلماتی که بیشترین شباهت را دارند با این مدل بدست آوریم. جدول ۱ شبیه ترین کلمات به کلمه مورد جستجو را با استفاده از نمایش های کلمه مدل ما و همچنین نمایش های کلمه LSA نشان می دهد. تمامی این بردارها شباهت های معنایی گسترده ای بدست می آورند. هرچند، به نظر می رسد که هر دو نسخه مدل ما در اجتناب از شباهت های توزیعی تصادفی (مثل شباهت screwball و grant به romantic) بهتر از LSA عمل کردند. مقایسه ای از دو نسخه مدل ما نیز اهمیت افزودن اطلاعات احساسی را روشن می سازد. به صورت کلی، کلمات نشان دهنده احساسات شباهت بالایی با کلماتی با همان قطبیت احساسی دارند، به همین دلیل حتی نتایج مدل های کاملا بدون نظارت نیز امیدوار کننده به نظر می رسند. اگرچه، آنها اثرات ژانر و محتوایی بیشتری هم نشان می دهند. برای مثال، بردارهای غنی شده با احساسات برای ghastly به درستی جایگزین های معنایی خوبی برای آن کلمه می باشند، در حالیکه بردارهای بدون احساسات نیز حاوی تعدادی کلمه محتوایی می باشند که ghastly به آنها اطلاق می شود. البته، اگرچه این تنها یک تحلیل برداشت گرایانه از چند نمونه است، اما در درک اینکه چرا مدل غنی شده با احساسات در نتایج طبقه بندی احساسی بهتر عمل می کند مفید خواهد بود.
۲-دیگر نمایش های کلمات:
برای مقایسه، ما چند مدل فضای برداری دیگر که از نظر مفهومی شبیه به مدل ما می باشند را نیز، همانطور که در بخش ۲ تشریح شد، پیاده سازی کردیم: 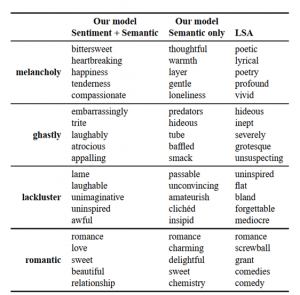 تحلیل معنایی پنهان (LSA؛ دیروستر و همکاران ۱۹۹۰) ما SVD کوتاه شده را روی یک ماتریس شمارش نرمال شده کسینوسی وزن دار tf.idf که یک طرح وزن دهی و هموارسازی استاندارد برای استنتاج VSM می باشد (تورنی و پنتل ۲۰۱۰) اجرا کردیم. تخصیص دیریکله پنهان (LDA؛ بلی و همکاران ۲۰۰۳) ما از مدل تشریح شده در بخش ۲ برای استنتاج نمایش های کلمات از ماتریس موضوعی استفاده کردیم. برای آموزش مدل LDA 50 موضوعی از کد منتشر شده توسط بلی و همکاران (۲۰۰۳) استفاده کردیم. ما از همان ۵۰۰۰ هزار اصطلاح لغت نامه برای LDA استفاده کردیم که برای آموزش مدل های بردار کلمات استفاده کرده بودیم. ما مقادیر هایپر پارامترهای LDA را به صورت پیش فرض نگه می داریم، اگرچه برخی نوشتجات اظهار می کنند که بهینه سازی پیشقدرها برای LDA حائز اهمیت است. متغیرهای وزن دهی ما هم وزن دهی تکرار اصطلاح با دلتای idf هموار (Δt’) باینری (b) و هم بدون idf (n) را ارزیابی می کنیم چرا که این متغیرها در آزمایش های قبلی در زمینه احساسات خوب عمل کردند (مارتینیو و فینین ۲۰۰۹؛ پنگ و همکاران ۲۰۰۲). در تمامی موارد، ما از استانداردسازی کسینوسی (c) استفاده می کنیم. پالتوگلو و تلوال (۲۰۱۰) یک تحلیل گسترده از چنین متغیرهای وزن دهی ای برای کاربردهای احساسی انجام داده اند.
تحلیل معنایی پنهان (LSA؛ دیروستر و همکاران ۱۹۹۰) ما SVD کوتاه شده را روی یک ماتریس شمارش نرمال شده کسینوسی وزن دار tf.idf که یک طرح وزن دهی و هموارسازی استاندارد برای استنتاج VSM می باشد (تورنی و پنتل ۲۰۱۰) اجرا کردیم. تخصیص دیریکله پنهان (LDA؛ بلی و همکاران ۲۰۰۳) ما از مدل تشریح شده در بخش ۲ برای استنتاج نمایش های کلمات از ماتریس موضوعی استفاده کردیم. برای آموزش مدل LDA 50 موضوعی از کد منتشر شده توسط بلی و همکاران (۲۰۰۳) استفاده کردیم. ما از همان ۵۰۰۰ هزار اصطلاح لغت نامه برای LDA استفاده کردیم که برای آموزش مدل های بردار کلمات استفاده کرده بودیم. ما مقادیر هایپر پارامترهای LDA را به صورت پیش فرض نگه می داریم، اگرچه برخی نوشتجات اظهار می کنند که بهینه سازی پیشقدرها برای LDA حائز اهمیت است. متغیرهای وزن دهی ما هم وزن دهی تکرار اصطلاح با دلتای idf هموار (Δt’) باینری (b) و هم بدون idf (n) را ارزیابی می کنیم چرا که این متغیرها در آزمایش های قبلی در زمینه احساسات خوب عمل کردند (مارتینیو و فینین ۲۰۰۹؛ پنگ و همکاران ۲۰۰۲). در تمامی موارد، ما از استانداردسازی کسینوسی (c) استفاده می کنیم. پالتوگلو و تلوال (۲۰۱۰) یک تحلیل گسترده از چنین متغیرهای وزن دهی ای برای کاربردهای احساسی انجام داده اند.
۳-طبقه بندی قطبیت متن:
اولین وظیفه ارزیابی ما یک طبقه بندی قطبیت احساسی سطح متن می باشد. یک طبقه بندی کننده باید پیش بینی کند که آیا یک نقد معین در یک متن نقد مثبت است یا منفی.
با در نظر گرفتن بردار صندوقچه کلمات ν یک متن، ما با استفاده از محصول ماتریس-بردار Rν ویژگی های مدل خود را بدست می آوریم که در آن ν می تواند وزن دهی دلخواه tf.idf را داشته باشد. ما استانداردسازی کسینوسی را روی ν اعمال نمی کنیم، بلکه در عوض استانداردسازی کسینوسی را روی بردار ویژگی نهایی Rν اعمال می کنیم. این رویه همچنین برای بدست آوردن ویژگی ها از بردار های کلمات LDA و LSA نیز کاربرد دارد. در آزمایش های اولیه، دریافتیم که هنگام ایجاد ویژگی های متن از طریق محصول Rν، وزن دهی ‘bnn’ بهتر از همه جواب می دهد. در تمامی آزمایش ها، ما از این وزن دهی برای بدست آوردن نمایش های چند کلمه ای از بردارهای کلمات استفاده می کنیم.
۱-۳ مجموعه داده نقد فیلم های پنگ و لی:
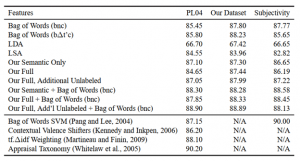
مجموعه داده قطبیت نسخه ۲٫۰ معرفی شده توسط پنگ و لی (۲۰۰۴) متشکل از ۲۰۰۰ نقد فیلم می باشد که یک برچسب قطبیت احساسی باینری به هر کدام از آنها تخصیص داده شده است. ما نتایج تصدیق متقاطع ۱۰ لایه را با استفاده از لایه های (folds) منتشر شده مولفان گزارش می دهیم تا نتایجمان با نتایج موجود در دیگر نوشتجات قابل مقایسه باشند. ما از یک طبقه بندی کننده ماشین بردار پشتیبانی (SVM) خطی که با LIBLINEAR آموزش دیده شده است (فن و همکاران ۲۰۰۸) استفاده کرده و مقدار پارامتر رگولاریزاسیون SVM را برابر با همان مقداری که پنگ و لی (۲۰۰۴) به کار برده بودند قرار دادیم. جدول ۲ عملکرد طبقه بندی متد ما، VSM های دیگری که پیاده سازی کردیم، و نتایج گزارش شده از نوشتجات قبلی را نشان می دهد. بردارهای صندوقچه کلمات به وسیله نشانه گذاری های وزن دهی شان مشخص می شوند. ویژگی های یاد گیرنده بردار کلمات با نام یاد گیرنده مشخص می شوند. به عنوان یک معیار کنترلی، ما نسخه های مدل خود را تنها با جزء معنایی بدون نظارت و مدل کامل (معنایی و احساسی) آموزش دادیم. همچنین نتایج نسخه مدل کامل که با ۵۰۰۰۰ مثال برچسب گذاری نشده اضافی آموزش داده شده است را نیز گنجاندیم. در آخر، برای آزمودن اینکه آیا نمایش های مدل های ما یک صندوقچه کلمات استاندارد تشکیل می دهند یا خیر، عملکرد نمایش های این دو ویژگی را با هم ارزیابی کردیم. ویژگی های متد ما به وضوح از ویژگی های VSM بهتر می باشند و هنگامی که با نمایش صندوقچه کلمات اصلی ترکیب می شود بهترین عملکرد را دارد. آن نسخه از مدل ما که با داده های برچسب گذاری نشده اضافه آموزش دیده بود بهترین عملکرد را داشت که نشان می دهد این مدل می تواند به طور موثر حجم زیادی از داده های برچسب گذاری نشده را همراه با مثال های برچسب گذاری شده مورد استفاده قرار دهد. متد ما علی رغم محدودیت با لغت نامه ای ۵۰۰۰ کلمه ای، کاملا می تواند با نتایج گزارش شده قبلی رقابت کند. ما عنوان فیلم را که در هر نقد وجود داشت استخراج کرده و دریافتیم که ۱۲۹۹ تا از ۲۰۰۰ نقد موجود در مجموعه داده ها حداقل یک نقد دیگر از همان فیلم در آن مجموعه داده دارند. از میان ۴۰۶ فیلم با چند نقد، ۲۴۹ تا برچسب قطبیت یکسانی در تمامی نقدهایشان داشتند. در کل، این اطلاعات نشان می دهند که به نسبت اندازه مجموعه داده، مثال های به شدت همبسته با برچسب های همبسته وجود دارند. این موضوع یک خصیصه طبیعی و قابل انتظار از این نوع جمع آوری متن می باشد، اما می تواند تاثیر قابل توجهی روی عملکرد در مجموعه داده هایی با این اندازه داشته باشد. در مدل های با لایه های تصادفی (random folds) توزیع شده توسط مولفان، تقریبا ۵۰% نقدها در مجموعه تست هر لایه اعتبارسنجی یک نقد از همان فیلم با همان برچسب در مجموعه آموزش دارند. به دلیل کوچک بودن مجموعه داده، یک یاد گیرنده می تواند با حفظ کردن برچسب ها و کلمات منحصر به یک فیلم مشخص (مثل نام کاراکترها یا عبارات داستان) عملکرد خوبی ارائه کند. ما مجموعه داده ای به اندازه قابل توجهی بزرگتر ارائه می دهیم که از مجموعه ها فیلم های مجزایی برای آموزش و تست استفاده می کند. این مراحل قابلیت اتکای یاد گیرنده به ارتباطات ویژه طبقه – کلمه را کمینه کرده و در نتیجه تمرکز را بر ویژگی های احساسی واقعی معطوف می سازند.
۲-۳ مجموعه داده نقد IMDB:
ما مجموعه ای از ۵۰۰۰۰ نقد فیلم از IMDB ایجاد کرده و بیش از ۳۰ نقد از یک فیلم در مجموعه جا ندادیم. تعداد نقدهای مثبت و منفی مجموعه داده ایجاد شده زوج می باشد، بنابراین حدس تصادفی منجر به دقت ۵۰% خواهد شد. با پیروی از تحقیقات قبلی روی طبقه بندی قطبیت، تنها نقدهای با قطبیت بالا را در نظر می گیریم. یک نقد منفی امتیازی ≥ ۴ از ۱۰ داشته و یک نقد مثبت امتیازی ≤ ۷ از ۱۰ دارد. نقدهای خنثی در این مجموعه داده قرار داده نشده اند. به منظور ارائه معیار سنجشی برای پژوهش های آتی در این زمینه، این مجموعه داده را در اختیار عموم قرار می دهیم. ما مجموعه داده را به صورت مساوی به مجموعه های های آموزشی و تستی تقسیم کردیم. مجموعه آموزشی همان ۲۵۰۰۰ نقد برچسب گذاری شده است که برای وارد کردن بردارهای کلمات به مدل استفاده شده اند. ما در تمام موارد عملکرد طبقه بندی کننده را بر اساس پارامترهای طبقه بندی کننده تصدیق متقاطع روی مجموعه آموزشی، و سپس با استفاده از یک SVM خطی ارزیابی کردیم. جدول ۲ عملکرد طبقه بندی را روی زیر مجموعه نقدهای IMDB ما نشان می دهد. مدل ما نسبت به روش های دیگر عملکرد بهتری داشته است و هنگامی که با نمایش صندوقچه کلمات ترکیب شده است بهترین عملکرد را ارائه می کند. همچنین نسخه ای از مدل ما که از داده های برچسب گذاری نشده اضافه استفاده کرده بود بهترین عملکرد را در زمان آموزش داشت. تفاوت های موجود در دقت کوچک می باشند، اما به دلیل اینکه مجموعه تستی ما ۲۵۰۰۰ مثال دارد، واریانس تخمین عملکرد بسیار پایین است. برای مثال، افزایش دقت ۰٫۱% با طبقه بندی صحیح ۲۵ نقد فیلم اضافه تر مطابقت خواهد داشت.
نتیجه گیری:
ما مدل بدون نظارت خود را طوری تعمیم دادیم تا اطلاعات احساسی را نیز شامل شود و نشان دادیم که این مدل تعمیم یافته چطور می تواند از فراوانی متون برچسب گذاری احساسی شده موجود در اینترنت برای رسیدن به نمایش های کلماتی که هم روابط احساسی را ثبت می کنند هم روابط معنایی را بهره ببرد. ما سودمندی چنین نمایش هایی را در وظیفه طبقه بندی احساسی با استفاده از مجموعه داده های موجود و همچنین در وظیفه بزرگتری که برای پژوهش های آتی منتشر خواهیم کرد به تصویر کشیدیم. این وظایف شامل اطلاعات احساسی به نسبت ساده ای می باشند، اما مدل ما در این زمینه بسیار انعطاف پذیر است؛ این مدل می تواند برای توصیف رنج وسیعی از تفسیرات استفاده شود و در نتیجه در زمینه های در حال رشد تحلیل و بازیابی احساسی بسیار مناسب اجرا است.
نویسنده: امیر کنارنگ





