



An Efficient Optimization Technique For Feature Subset Selection For Machine Learning
بیان مساله: این مقاله دقیقا چه مساله ای را حل می کند؟
انتخاب زیر مجموعه ای از ویژگیی ها، یکی از حوزه های فعال تحقیقات در مبحث یادگیری ماشین می باشد که برای مسائل رگرسیون و دسته بندی بسیار کاربرد داشته ، استفاده می شود. تکنیکها و روشهای مختلف برای انتخاب زیر مجموعه بهینه از ویژگی ها ساخته و ارائه شده است دلیل آن هم اهمیت و تاثیر بسزایی است که برکارایی الگوریتم های یادگیری ماشین دارد.
در این مقاله یک روش نوین برای یافتن زیرمجموعه ای بهینه از ویژگی ها مطرح شده که در آن یک الگوریتم طی فرایندی تکراری بهینه محلی را پیدا کرده به همراه الگوریتم های انتخاب ویژگی به کار گرفته شده و زیر مجموعه بهینه از ویژگی ها را ارائه می دهد.
فرضیات مساله: برای حل مساله چه فرضیات در نظر گرفته شده است؟
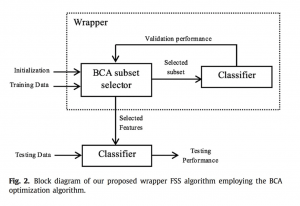
از روش Wrapper برای انتخاب زیرمجموعه ویژگیی ها استفاده شده است. برای بهینه کردن زیر مجموعه ویژگیی انتخاب شده توسط متد Wrapper از الگوریتم بهینه سازی BCA که در همین مقاله معرفی شده است استفاده شده. ویژگی های انتخاب شده در مساله Classification مورد استفاده قرارگرفته اند. الگوریتم های Classification ای که برای برسی سازگاری FSS با روش Wrapper و رویکرد BCA مورد استفاده قرارگرفته اند عبارتند از : MLP – Naïve Bayes – SVM
۷مجموعه داده برای آموزش استفاده شده اند که تعدادی از آنها دو کلاسه و تعدادی چند کلاسه هستند و محدوده تعداد ویژگی ها بین ۱۸تا ۷۹ متغییر است.
۷۰درصد از داده های هر مجموعه داده به عنوان مجموعه داده آموزش مورد استفاده قرار گرفته و بقیه Test وValidation برای نحوه نمایش و Representation مساله به صورت باینری است.

راه حل های قبلی: روش های دیگران برای حل این مساله چه چیزهایی بودند؟
در حالت کلی می توان روش های FSS را به ۴ دسته Hybrid ،Wrapper ، Filter و متدهای Embedded دسته بندی کرد. روش فیلتر توسط یک اندازه گیری، امتیاز معنا داری به ترکیب های مختلف Featureها بدون در نظر گرفتن الگوریتم Classification مورد استفاده، نسبت می دهد. معیار همبستکی و اطلاعات متقابل MI دو معیار اندازه گیری متداول در این تکنیک هستند. در روش Wrapper از یک معیار ارزیابی وابسته به الگوریتم بهره برده می شود تا مفید بودن زیر مجموعه ویژگیی ها با یک روش تکرار شونده ، مشخص شود.
در روش Hybridهر دو متد Wrapper و Filter به کار گرفته می شوند تا FSS تقویت شود. برای داده های با ابعاد بالا عموما از روش Hybrid بهره برده می شود که WISS و ورژن ارتقا یافته آن WISSr از این دسته هستند.
برخلاف دسته های ذکر شده، تکنیک های Embedded مانند درخت تصمیم و SVM هدفشان را مستقیما با در نظرگرفتن FS به عنوان بخشی از هدف بهینه سازی الگوریتم یادگیری عملی می کنند. از روش Wrapper به صورت گسترده برای مسایل Classification استفاده می شود چرا که توسط Wrapper FSS زیرمجموعه ای از ویژگی ها انتخاب شده الگوریتم دسته بندی توسط آن آموزش می بیند و عملکرد برتری از خود نشان می دهند.
متاهیوریستیک های ترتیبی و تصادفی مانند SA،PSO ، GA و… نمونه هایی از استرتژی های جستجوی تصادفی هستند که در مسایل انتخاب ویژگی مورد استفاده قرار میگیرند. علیرغم پیشرفت های حاصل از روش های پیشرفته تصادفی بهنیه سازی گراف، آنها کاملا رضایت بخش نبودند چرا که ممکن است جواب بهینه بدست آورند و یا از نظر بار محاسبات قابل پیاده سازی نبوده و عملی نباشند. راهکارهای شناخته شده و معروف جستجوی قطعی به طور خاص برای FSS وجود دارد مانند SFSS و SFS که الگوریتم پیشنهاد شده در این مقاله با آن مقایسه می شود.
نوآوری: نوآوری این مقاله چیست؟
در این مقاله روش نوین به نام (BCA (Binary Coordinate Ascent که الهام گرفته شده از الگوریتم مختصات نزولی، Coordinate Descent معرفی شده است. الگوریتم بهینه سازی BCA با رویکرد بهینه سازی قطعی محلی، جستجوی خود را از یک نقطه ی اولیه در فضایی از نمایش باینری متغییرهای ورودی و خروجی های پیوسته، شروع می کند. به روز کردن Solution را با بهینه کردن تابع هزینه برای هر مختصات (یکی در هر زمان) تکرار می کند.
رویکرد BCA در روش بر پایه Wrapper FSS برای مساله Classification مورد استفاده قرار گرفته است تا تعداد زیاد زیرمجموعه هایی که توسط روش های قبلی FS بدست میامد را کاهش دهد. در راستای پیدا کردن بهترین زیرمجموعه از ویژگی ها (زیرمجموعه بهینه)، AUC کلسیفایر که برای مشخص کردن کارایی تعمیم (Generalization) سیستم طبقه بندی مورد استفاده قرار میگیرد، ۱۰-fold CV به دست آمده، به عنوان معیار ارزیابی تعیین سودمندی زیر مجموعه های مختلف تعیین شده است. تا کنون محقق دیگری از الگوریتم BCA استفاده نکرده و الگوریتم FSSای بر پایه آن توسعه نیافته است.
راه حل پیشنهادی: قسمت های مختلف راه حل پیشنهادی و کاربرد هر یک چیست؟
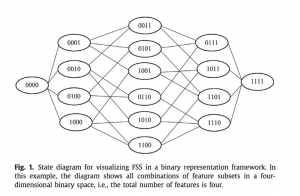
در بسیاری از مسایل برنامه نویسی میتوان از نمایش باینری برای ورودی ها استفاده کرد و میتوان این روش را برای Encode کردن فضای ورودی به کار برد. FSS یکی ازاین الگوریتم ها است. فرم اصلی بهینه سازی بدون محدودیت برای ماکزیمم سازی تابع هدف پیوسته در فضای دودویی مطرح می شود. اگر تعداد Variableها کم باشد یک جستجوی کامل میتواند انجام شود اما در حالت کلی این مساله NPhard است. بسیاری از روش های تکاملی مانند Swarmو بهینه ساز های تکاملی برای حل این مشکل مورد استفاده قرار گرفته اند تا به جواب Sub-optimal برسیم. استفاده از این روش های بهینه سازی هزینه بر هستند، در نتیجه از BCA استفاده می کنیم.
BCA از یک نقطه اولیه در فضای جستجو شروع می کند. بردار دودویی در ابتدا تماما صفر است. در ادامه BCA این جواب را به وسیله Max کردن تابع هدف برای هر مختصات به صورت جداگانه، به روز می کند. هنگامی که BCA یک جستجو میان همه مختصات ها انجام داد – میگوییم یک BCA Scan انجام شد – جواب * Yرا Update می کند. الگوریتم زمانی متوقف می شود که دیگر تغییر قابل ملاحظه ای در مقدار بهینه تابع هدف اتفاق نیفتد. تعداد کل تکرار ها را می توان بعدا با S×N(تعداد کل اسکن ها × بعد مساله) بدست آورد. الگوریتم در
نهایت یک جفت * Yو * X به عنوان نقطه Max به ما می دهد.
سودوکد الگوریتم :

بر پایه رویکرد بهینه سازی BCA یک Fast Wrapper با دو استراتژی مقداردهی اولیه می شود:
-1شروع از یک مجموعه خالی از ویژگیی ها – BCA-Zero
-2شروع از یک مجموعه با تعدادی ویژگی – BCA-Initialized
N تعداد کل ویژگی ها است. هر زیرمجموعه از ویژگی ها به صورت یک بردار با انداره N نمایش داده می شود. هر بخش ازین بردار به یک ویژگی مرتبط است. اگر آن ویژگی در جواب ما حضور داشته باشد مقدار آن برابر ۱ اگر نباشد ۰ در نظرگرفته می شود.
در روش BCA-Zero از یک مجموعه خالی یعنی بردار تماما صفر شروع می کند، BCA به صورت تکراری ویژگی هایی را به بردار اضافه وکم می کند تا ببیند بر اساس تابع هدف بودن آن ویژگی موجب افزایش کارایی Classifier می شود یا عدم حضور آن. در واقع تابع هدف عملکرد اعتبارسنجی یک Classifier از پیش تعیین شده که از اعتبار سنجی ۱۰-fold CV بر روی داده اعتبار سنجی بدست آمده است می باشد.
هنگامی که الگوریتم به یک جواب نهایی همگرا شد، بهترین زیرمجموعه ویژگی های بدست آمده، کلسیفایر برای آن تعداد ویژگی ها آموزش داده می شود و توسط مجموعه اعتبار سنجی و تست، مورد بررسی قرار می گیرد. برای مشخص کردن و بررسی سازگاری کلسیفایرها با روش های MLP ، SVM و NB آموزش داده می شوند.
 در روش BCA-Initialized کلیه مراحل مانند BCA-Zero است با این تفاوت که به جای شروع از یک زیرمجموعه خالی (بردار تماما صفر) از یک مجموعه اولیه بر اساس Rank ویژگی ها شروع می کنیم، بالاترین AUC ها را مثلا % Tاولیه بالاترین ها به عنوان ویژگی ها برای مقداردهی اولیه زیرمجموعه انتخاب می کنیم T. متغییر است که توسط کاربر و بر اساس تجربه، تعداد ویژگی ها و شناخت روی مجموعه داده تنظیم می شود. برای نشان دادن کارایی و بهره وری روش ،BCA FSS الگوریتم با دو تکنیک معروف بر پایه Wrapper FSS یعنی SFS و SFSS همینطور روش هیبریدی IWSSr مقایسه شده است.
در روش BCA-Initialized کلیه مراحل مانند BCA-Zero است با این تفاوت که به جای شروع از یک زیرمجموعه خالی (بردار تماما صفر) از یک مجموعه اولیه بر اساس Rank ویژگی ها شروع می کنیم، بالاترین AUC ها را مثلا % Tاولیه بالاترین ها به عنوان ویژگی ها برای مقداردهی اولیه زیرمجموعه انتخاب می کنیم T. متغییر است که توسط کاربر و بر اساس تجربه، تعداد ویژگی ها و شناخت روی مجموعه داده تنظیم می شود. برای نشان دادن کارایی و بهره وری روش ،BCA FSS الگوریتم با دو تکنیک معروف بر پایه Wrapper FSS یعنی SFS و SFSS همینطور روش هیبریدی IWSSr مقایسه شده است.
مقایسه بر اساس کارایی طبقه بندی کننده – تعداد ویژگی های انتخاب شده – تعداد زیرمجموعه های بدست آمده – زمان پردازش صورت گرفته است.
ارزیابی: راه حل پیشنهادی روی چه داده هایی پیاده سازی شده اند؟
از ۷ مجموعه داده مستقل با تعداد زیاد نمونه (درحدود ۱۸۴۶) برای پیاده سازی استفاده شده است.
۶ تا از مجموعه داده ها را می توان از طریق سایت UCI دسترسی داشت .
| DataSet | Number Of Instances | Number Of Attributes | Number Of Classes |
| Sonar | ۲۰۸ | ۶۰ | ۲ |
| Landsat | ۶۴۳۵ | ۳۶ | ۶ |
| Parkinson | ۱۹۵ | ۲۲ | ۲ |
| Climate | ۵۴۰ | ۱۸ | ۲ |
| Segmentation | ۲۳۱۰ | ۱۹ | ۷ |
| Breast Cancer | ۵۶۹ | ۳۰ | ۲ |
۷امین مجموعه داده Polyp است. یک مجموعه داده پزشکی شامل ۲۶۷۰ کاندید پلیپ که برای هر کدام ۷۹ ویژگی مختلف از عکسبرداری ها،آزمایش ها و … وجود دارد.
| DataSet | Number Of Instances | Number Of Attributes | Number Of Classes |
| Polyp | ۲۶۷۰ | ۷۹ | ۲ |
در پایان از ۵ مجموعه داده دیگرکه تعداد نمونه های آن کم اما تعداد ویژگی های آن زیاد است برای ارزیابی الگوریتم استفاده شده است.
| DataSet | Number Of Instances | Number Of Attributes | Number Of Classes |
| Colon | ۶۲ | ۲۰۰۰ | ۲ |
| Leukemia | ۷۲ | ۷۰۷۰ | ۲ |
| ALLAML | ۷۲ | ۷۱۲۹ | ۲ |
| Prostate | ۱۰۲ | ۵۹۶۶ | ۲ |
| CLL_SUB | ۱۱۱ | ۱۱۳۴۰ | ۳ |
نتایج: نتایج شبیه سازی چگونه بوده است؟
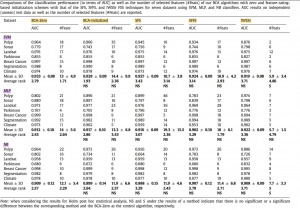
نتایج کارایی AUC بر اساس مقادیر و تعداد ویژگی هایی که برای الگوریتم استفاده شده :
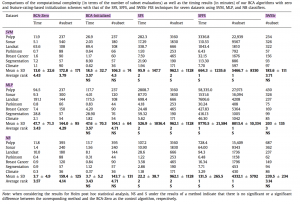
 مقایسه پیچیدگی محاسباتی بر اساس زمان و تعداد زیر مجموعه هایی که محاسبه کرده :
مقایسه پیچیدگی محاسباتی بر اساس زمان و تعداد زیر مجموعه هایی که محاسبه کرده :
 آنالالیز overlapping ویژگی ها بین هر دو جفت الگوریتم های – Wrapper FSS شباهت بر اساس معیار Jaccard:
آنالالیز overlapping ویژگی ها بین هر دو جفت الگوریتم های – Wrapper FSS شباهت بر اساس معیار Jaccard:
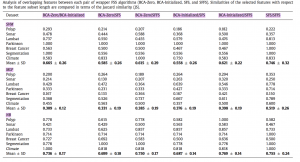 نتایج بدست آمده نشان می دهد استفاده از BCA موجب کاهش زمان پردازش و تعداد زیرمجموعه ها شده است.
نتایج بدست آمده نشان می دهد استفاده از BCA موجب کاهش زمان پردازش و تعداد زیرمجموعه ها شده است.
روش BCA در مقایسه با IWSSr تعداد subsetهای محاسبه شده کاهش یافته این نتایج هنگامی که ابعاد مساله بالاست بیشتر خود را نشان می دهد و تفاوتشان بیشتر است.
مقایسه کامل :
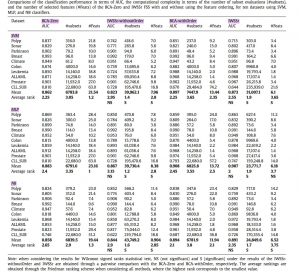
پیچیدگی مساله BCA خطی است اما SFS و SFSS پیچیدگی از مرتبه ۲ دارند. نتایج نشان می دهد روش مطرح شده روش مناسبی برای بهینه سازی مخصوصا مسایل دسته بندی با تعداد زیاد ویژگی می باشد.
کارهای آینده:
آیا مقاله پیشنهادی برای ادامه کار داشته است؟ اگر نداشته پیشنهاد شما چیست؟
برای ادامه کار در مقاله پیشنهاد شده که بر نحوه و استراتژی مقداردهی های اولیه و تکنیک مرتب سازی ویژگی ها کار شود.
نقاط قوت:
از دیدگاه شما نقاط قوت مقاله چیست؟
در این مساله یک روش بهینه سازی مطرح شده. نمایش باینری مساله درک بهتری از مساله داده پیاده سازی آن را آسان تر می کند. از نظر پیچیدگی محاسبات و زمانی عملکرد مناسبی از خود نشان داده پیچیدگی آن خطی می باشد. بعد از اسکن های متداول حتما یک جواب Optimal یا Sub-optimal به ما می دهد.
نقاط ضعف:
از دیدگاه شما نقاط ضعف مقاله چیست؟
در روش های مقدار دهی اولیه بردار باینری دو روش BCA-Zero و BCA-Initialized مطرح شد که در روش اول از مجموعه خالی جستجو شروع می شد و در روش دوم از یک مجموعه شامل تعدادی ویژگی – به صورت بد بینانه و خوش بینانه مساله مورد برسی قرار گرفته – در نظرگرفتن روشی که در آن ویژگی ها با rank مستقل پایین تر هم شانس شرکت را داشته باشند ممکن است رسیدن به Optimum چه سراسری چه محلی را بیشتر کند.
دانشگاه آزاد اسلامی واحد تهران شمال
موضوع : گزارش تحقیقاتی
استاد محترم : دکتر منثوری
نام و نام خانوادگی گرداورنده : عسل میردوزنده
سال پذیرش : May 2016
BINARY COORDINATE ASCENT:
AN EFFICIENT OPTIMIZATION TECHNIQUE
FOR FEATURE SUBSET SELECTION
FOR MACHINE LEARNING
ELSEVIER – KNOWLEDGE-BASED SYSTEM
KEYWORD:
MACHINE LEARNING, CLASSIFICATION , FEATURE SELECTION, WRAPPER, OPTIMIZATION





