CLUE – Cluster-Based Retrieval of Images by Unsupervised Learning
پیاده سازی روش Clue به منظور بازیابی تصاویر : با توسعه ی اینترنت و قابلیت دستگاه های تصویربرداری از قبیل دوربین های دیجیتال، مجموعه تصاویر دیجیتال به سرعت در حال گسترش هستند. جستجوی کارآمد تصویر و نیز ابزارهای بازیابی برای کاربران در زمینه های مختلف مانند جلوگیری از جرم و جنایت، کاربردهای پزشکی و معماری ضروری است. برای رسیدن به این اهداف کاربردی، سیستم های بازیابی تصویر همه منظوره در دو قالب اصلی توسعه یافته اند.
- مبتنی بر متن
- مبتنی بر محتوا
ابتدا در سال ۱۹۷۰ دیدگاه مبتنی بر متن مطرح شد که در چنین سیستم هایی، تصاویر به طور دستی توسط توصیفگرهای متن تفسیر حاشیه نویسی می شوند، سپس سیستم مدیریت پایگاه داده برای بازیابی تصویر از آن ها استفاده می کند. دو ایراد اصلی به این روش وارد است:
نیروی انسانی زیادی برای تفسیر دستی لازم است.
حاشیه نویسی تصویر بی دقت است؛ زیرا توسط نیروی انسانی انجام می گرفت. از طرفی چون افراد معیارهای شخصی خودشان را در حاشیه نویسی اعمال می کنند این عمل حالت سلیقه ای و غیر قطعی پیدا می کند. برای رفع مشکلات ذکر شده در سیستم های بازیابی مبتنی بر متن، بازیابی تصویر مبتنی بر محتوا (CBIR) در اوایل ۱۹۸۰ معرفی شد. در روش های مبتنی بر محتوا، تصاویر براساس محتوای بصری، از قبیل رنگ، بافت و شکل دسته بندی می شوند. در سال ۱۹۸۸ اولین مقاله توسط Chang منتشر شد که در آن نویسنده یک دیدگاه شاخص گذاری و انتزاعی برای بازیابی پایگاه داده تصویر به صورت هوشمند ارائه کرده است. پایگاه داده تصویر، شامل اشیاء و روابط تصویری است که برای ساخت شاخص های تصویری، عملیات انتزاعی برای خوشه بندی و نیز دسته بندی تصاویر اعمال شده است. در دهه گذشته در راستای بهبود روش های بازیابی تصویر مبتنی بر محتوا، روش های متعددی ارائه شده است که به عنوان نمونه هایی از سیستم های آزمایشی نمونه اولیه می توان به موارد زیر اشاره کرد:
شکاف معنایی:
تفاوت بنیادی بین سیستم های بازیابی مبتنی بر محتوا و متن این است که تعامل بشری یک بخش ضروری برای سیستم های مبتنی بر متن است. انسان ها میل به استفاده از ویژگی های سطح بالا (مفاهیم ) از قبیل کلمات کلیدی، توصیفگر متن برای تفسیر و اندازه گیری شباهت های آنها دارند. ویژگی هایی که با استفاده از تکنیک های بینایی کامپیوتر به طور خودکار استخراج می شوند اکثرا ویژگی های سطح پایین هستند(رنگ، بافت، شکل، طرح بندی مکانی و غیره). به طور کلی ، هیچ ارتباط مستقیمی بین مفاهیم سطح بالا و ویژگی های سطح پایین وجود ندارد .
با وجود آنکه ، بسیاری الگوریتم های پیچیده برای توصیف ویژگی های رنگ ، شکل و بافت طراحی شده اند ، این الگوریتم ها نمی توانند به طور مناسب معنای تصویر را مدل کنند و محدودیت های بسیاری در مواجهه با پایگاه داده های تصویری با محتوای گسترده دارند. آزمایشات گسترده روی سیستم های CBIR نشان می دهد که مفاهیم سطح پایین اغلب قادر به توصیف مفاهیم معنایی سطح بالای مغز انسان نیستند. بنابراین ، کارایی CBIR هنوز از انتظارات کاربران دور است .
Eakins به سه سطح از پرس و جو ها در CBIR اشاره می کند :
سطح ۱ : بازیابی با ویژگی های ابتدایی مثل رنگ ، بافت ، شکل یا موقعیت مکانی عناصر تصویر . این نمونه پرس و جو ، پرس و جو با مثال است . “تصویری مثل این پیدا کن”
سطح ۲ : بازیابی اشیاء از نوع معرفی شده(نوع مشخص شناسایی شده) با ویژگی های استنتاج شده با درجه ای از استنباط منطقی . برای مثال “تصویر یک گل را پیدا کن .”
سطح ۳ : بازیابی با ویژگی های انتزاعی ، شامل میزان قابل توجهی استدلال سطح بالا درباره ی هدفِ اشیاء یا نمایش منظره. این شامل بازیابی رویدادهای مشخص از تصاویری با اهمیت احساسی یا مذهبی است و غیره . “مثال : تصویری از یک جمعیت شاد را جستجو کن . ”
سطح های ۲ و ۳ با هم بازیابی معنایی تصویر را بیان می کنند و شکاف بین سطوح ۱ و ۲ شکاف معنایی است. می توان به طور خاص اینطور بیان کرد که تفاوت بین قدرت توصیفی محدود ویژگی های سطح پایین و توانایی معنایی کاربر به عنوان شکاف معنایی یاد می شود.
کاربران در بازیابی سطح ۱ معمولا باید یک تصویر نمونه یا طرح را به عنوان پرس و جو ارائه کنند . اما اگر کاربر تصویر نمونه ای را نداشته باشد چه باید کرد؟ در چنین شرایطی بازیابی معنایی تصویر برای کاربران بسیار مناسب است چون پرس و جو با کلمه کلیدی یا الگو (بافت) را پشتیبانی می کند.
بنابراین برای پشتیبانی پرس و جو با مفاهیم سطح بالا ، یک سیستم CBIR باید پشتیبانی کاملی برای پر کردن شکاف معنایی بین ویژگی های شمارشی(عددی) تصویر و توانایی معنایی بشر ارائه دهد.
ویژگی های سطح پایین تصویر
استخراج ویژگی سطح پایین تصویر اساس سیستم های CBIR است. برای اجرای CBIR ویژگی های تصویر می توانند از کل یا ناحیه ای از تصویر استخراج شوند. چون کاربران معمولاً به ناحیه ای خاص از تصویر نسبت به کل تصویر علاقه مندتر هستند، بنابراین اکثر سیستم های CBIR مبتنی بر ناحیه هستند. بازیابی مبتنی بر ویژگی عمومی نسبتاً ساده تر است. ثابت شده است که نمایش تصاویر در سطح ناحیه بسیار به سیستم درک انسان نزدیکتر است. در این مقاله ، بر بازیابی تصویر مبتنی بر ناحیه (RBIR) تمرکز شده است. برای انجام RBIR اولین قدم پیاده سازی قطعه بندی تصویر است . سپس ، ویژگی های سطح پایین مثل رنگ ، بافت ، شکل یا موقعیت فضایی می توانند از نواحی قطعه بندی شده استخراج شوند.شباهت بین دو تصویر بر مبنای ویژگی های ناحیه مشخص می شود.این بخش شامل توصیف مختصری از ۳بخش که روی سیستم RBIR با مفاهیم سطح پایین تمرکز می کند است.
قطعه بندی تصویر
قطعه بندی خودکار تصویر یک کار مشکل است. تکنیک های متفاوتی در گذشته برای این کار پیشنهاد شده اند از قبیل : Curve Evolution، Energy Diffusion و Graph Partitioning.
تکنیک های قطعه بندی موجود، از قبیل متدهای خوشه بندی مستقیم، برای تصاویری که فقط شامل نواحی رنگ همگن هستند در فضای رنگ خوب کار می کنند. این تکنیک ها به سیستم های بازیابی اعمال می شوند که تنها با رنگ ها کار می کنند . اما منظره ی طبیعی پر از رنگ و بافت است . بافت یک ویژگی مهم در تعریف مفاهیم سطح بالا است. بافت عمده ی دشواری در یک متد قطعه بندی است . بسیاری الگوریتم های قطعه بندی بافت نیازمند تخمین پارامترهای مدل بافت هستند که این کار بسیار مشکلی است .قطعه بندی JSEG بر این مشکلات چیره شد. به جای تلاش برای یک مدل خاص برای ناحیه ی بافت ، بر همگنی (یکنواختی) یک الگوی رنگ – بافت ارائه شده تلاش می کند . JSEG از دو گام تشکیل شده است. در گام اول ، رنگ های تصویر در چندین کلاس ارزیابی می شوند . با جایگزینی پیکسل های تصویر با برچسب های کلاس رنگ متناظر می توانیم یک کلاس نگاشت از تصویر بدست آوریم. سپس قطعه بندی فضایی روی این کلاس نگاشت اجرا می شود که می تواند به عنوان یک نوع ترکیب بافت خاص در نظر گرفته شود .الگوریتم نواحی همگن رنگ – بافت ایجاد می کند و در بسیاری از سیستم ها استفاده می شود شکل ۱-۱ مثالی را نشان می دهد.

شکل ۱-۱- نتایج قطعه بندی JSEG
قطعه بندی Blobworld الگوریتم قطعه بندی دیگری است که به طور گسترده استفاده می شود. این الگوریتم با خوشه بندی پیکسل ها در یک فضای پیوسته ویژگی رنگ – بافت – موقعیت بدست می آید. در مرحله ی اول، توزیع پیوسته ویژگی رنگ ، بافت و موقعیت با یک ترکیب از Gaussians مدل می شوند . سپس الگوریتم بیشینه ساز پیش بینی (EM) برای تخمین پارامترهای مدل استفاده می شوند. عضو پیکسل – خوشه نتیجه یک قطعه بندی از تصویر را ارائه می دهد. نواحی حاصل تقریباً مطابق با اشیاء هستند.
برخی سیستم ها قطعه بندی های خود را به منظور بدست آوردن ویژگی های ناحیه ی مورد نظر در حین قطعه بندی طراحی کرده اند که رنگ ، بافت یا هردو هستند. این الگوریتم ها معمولاً مبتنی بر خوشه بندی K-means از ویژگی های پیکسل/بلاک هستند. الگوریتم خوشه بندی k-means برای خوشه بندی بردارهای ویژگی به چندین کلاس که هر کلاس متناظر با یک ناحیه است اعمال می شود.بلاک ها در کلاس یکسان به ناحیه یکسان دسته (رده) بندی می شوند.
KMCC ) k-means با قید اتصال) برای قطعه بندی اشیاء در تصاویر پیشنهاد شده است . که توسعه ی یافته ی الگوریتم k-means است .در این الگوریتم مجاورت فضایی هر ناحیه با تعریف یک مرکز جدید برای الگوریتم k-means و یکپارچه کردن k-means با یک پروسه برچسب زنی مولفه به حساب می آید.
استفاد از الگوریتم قطعه بندی به نیازهای سیستم و مجموعه داده استفاده شده بستگی دارد . قضاوت در مورد اینکه کدام الگوریتم بهترین است مشکل است . برای مثال JSEG نواحی همگن رنگ-بافت را ارائه می کند در حالیکه KMCC به دنبال بدست آوردن اشیائی است معمولاً همگن نیستند . در مقایسه با JSEG، KMCC از نظر محاسباتی قوی تر است . اما به نظر می رسد که قطعه بندی های JSEG و Blobworld تا کنون به طور وسیع تری استفاده شده اند.
ویژگی های سطح پایین تصویر
اینجا ما روی ویژگی های استفاده شده در سیستم RBIR با مفاهیم سطح بالا تمرکز می کنیم.
ویژگی رنگ
ویژگی رنگ یکی از ویژگی هایی است که به طور گسترده در بازیابی تصویر استفاده می شود . رنگ ها در یک فضای رنگی انتخاب شده ، تعریف می شوند. فضاهای رنگ مختلفی وجود دارند ، که اغلب برای کاربردهای متفاوتی استفاده می شوند. فضاهای رنگ نشان می دهند که به درک انسان نزدیکتر هستند و به طور گسترده در RBIR شامل RGB ، LAB ، LUV ، HSV (HSL) ، YCrCb وتفاضل رنگ حداکثر و حداقل (HMMD) استفاده می شوند . معمولترین ویژگی های رنگ یا توصیفگرها در سیستم های RBIR استفاده می شوند به ترتیب زیر هستند :
- Color-Covariance Matrix
- Color Histogram
- Color Moments
- Color Coherence Vector
Mpeg-7 شامل Dominant color ، Color structure ، Scalable color و Color layout به عنوان ویژگی های رنگ است.اکثر این ویژگی های رنگ با وجود آنکه برای توصیف رنگ ها کارآمد هستند اما به طور مستقیم به مفاهیم سطح بالا مربوط نیستند. برای نگاشت مناسب رنگ ناحیه به نام های رنگ معنایی سطح بالا ، برخی سیستم ها از میانگین رنگ تمام پیکسل ها در یک ناحیه به عنوان ویژگی رنگ استفاده می کنند . اما بیشتر قطعه بندی ها مایل به ارائه ی نواحی بارنگ همگن هستند به علت عدم دقت قطعه بندی ، میانگین رنگ می تواند از نظربصری از ناحیه اصلی متفاوت باشد . Liu یک رنگ غالب در فضای HSV را به عنوان رنگ ادراکی یک ناحیه تعریف کرده است. رنگ غالب در فضاب HSV بعنوان رنگ دریافتی از یک ناحیه تعریف شده است. ابتدا هیستوگرام فضای رنگ HSV ناحیه رسم می شود . و bin با اندازه ماکزیمم انتخاب می شود. سپس مقدار HSV میانگین از همه پیکسل های bin انتخاب شده بعنوان رنگ غالب انتخاب می شود.
در بیشتر موارد ، رنگ میانگین و رنگ غالب بسیار به هم شبیه هستند ، مثل شکل ۲(۱) . اما در برخی موارد می تواند بسیار متفاوت باشد مثل شکل ۲(۲). پس باید توجه کرد که انتخاب ویژگی های رنگ بستگی به نتایج قطعه بندی دارد.

شکل ۲-۱- رنگ غالب و رنگ میانگین . (الف) رنگ اصلی ، (ب) رنگ میانگین ، (ج) رنگ غالب.
ویژگی بافت
بافت به خوبی ویژگی های رنگ شناخته شده نیست ، برخی سیستم ها از ویژگی های بافت استفاده نمی کنند. اما ، بافت اطلاعات مهمی در رده بندی تصویر ارائه می کند چون محتوای بسیاری از تصاویر دنیای واقعی مثل پوست میوه ، ابرها ، درخت ها ، اجرها و پارچه بافت هستند. از اینرو بافت یک ویژگی مهم تعریف معانی سطح بالا برای هدف بازیابی تصویر است .
ویژگی های بافت که معمولاً در سیستم های بازیابی تصویر استفاده می شوند شامل ویژگی های طیفی هستند مثل ویژگی هایی که با استفاده از فیلترینگ Gabor یا تبدیل wavelet بدست می آیند. ویژگی های آماری بافت را برحسب اندازه های آماری محلی توصیف می شوند. مثل شش ویژگی بافت Tamura و ویژگی های wold که توسط Liu et al. پیشنهاد شده اند . شش ویژگی بافت Tamura به ترتیب زیر هستند :
- Coarseness
- Directionality
- Regularity
- Contrast
- Line-Likeness
- Contrast
- Roughness
MPEG-7 ، regularity ، directionality و coarseness را به عنوان توصیفگر مرور بافت اعمال می کند. از میان ویژگی های بافت متفاوت ، ویژگی های Gabor و ویژگی های wavelet به طور گسترده برای بازیابی تصویر استفاده می شوند و گزارش شده است که به خوبی مطابق با مطالعه ی بینایی انسان هستند . فیلترینگ Gabor و تبدیل waveletدر اصل برای تصاویر مستطیلی طراحی شده اند. اما نواحی در سیستم های RBIR از شکل های اختیاری هستند . چگونه ویژگی های بافت را از شکل های اختیاری در سیستم های RBIR استخراج کنیم؟
در برخی سیستم ها ویژگی های بافت بر مبنای خصوصیت بافت پیکسل ها یا بلاک های کوچک موجود در ناحیه بدست می آیند. مشکل چنین ویژگی این است که نمی تواند به طور موثر خصوصیت بافت کل ناحیه را توصیف کند . یک راه شهودی برای حل این مشکل توسعه ی ناحیه شکل دلخواه به یک ناحیه ی مستطیلی با پرکردن برخی مقادیر در خارج از مرز و سپس اعمال تبدیل بلاک است . اما چون نواحی در تصاویر دنیای واقعی معمولاً بافت همگن نیستند ، چنین پرکردن اولیه ای مولفه های بدلی را نشان می دهد که ناحیه ی اصلی را توصیف نمی کند و از اینرو کارایی ویژگی بافت بدست آمده را پایین می آورد. راه حل ممکن دیگر، بدست آوردن یک مستطیل داخلی (IR) از یک ناحیه که تبدیلات بلاک می توانند بر آن برای تولید ضرایب که از آن ویژگی بافت می تواند محاسبه شود اجرا شوند است . این وقتی که بافت ناحیه همگن است و IR اطلاعات کافی را برای توصیف خصوصیت بافت ناحیه دربردارد خوب کار می کند .اما نواحی تصاویر در دنیای واقعی معمولاً همگن نیستند . به علاوه در بسیاری موارد می توانیم یک IR که یک بخش کوچک از ناحیه اصلی را پوشش می دهد بدست آوردیم . از اینرو ، ویژگی بافت بدست آمده از IR نمی تواند به خوبی خصوصیت کل ناحیه را نشان دهد.برای حل این مشکل ، یک الگوریتم استخراج ویژگی بافت کارآمد برای ناحیه های با شکل اختیاری ارائه شده است .
توصیفگر هستوگرام لبه (EHD) برای نمایش تصاویر طبیعی بسیار کاراست . یک توزیع فضایی از لبه ها را میگرد ، تا حدی شبیه به توصیفگر color layout . برای محاسبه ی EHD تصویر ارائه شده ابتدا به زیر تصاویر ۴*۴ تقسیم می شود و هیستوگرام های لبه ی محلی برای هر یک از این زیر تصاویر محاسبه می شود . لبه ها به طور کلی در ۵ دسته قرار می گیرند : vertical ، horizontal ، ۴۵◦ ، ۱۳۵◦و خنثی(neutral) .
شکل۳-۵-۱
ویژگی های شکل از لحاظ کاربردی شامل موارد زیر هستند:
- Aspect Ratio
- Circularity
- Fourier Descriptors
- Moment Invariants
- Consecutive Boundary Segments
ویژگی های شکل ویژگی های تصویری مهمی هستند با وجود این به طور گسترده مثل ویژگی های رنگ و بافت در RBIR استفاده نمی شوند . نشان داده شده است که ویژگی های شکل در بسیاری تصاویر با دامنه خاص مثل اشیاء مصنوعی (ساخت بشر) مفید هستند. برای تصاویر رنگی در بسیاری از مقاله ها با وجود اینکه اعمال ویژگی های شکل در مقایسه با رنگ و بافت به علت عدم دقت و صحت قطعه بندی مشکل است استفاده شده اند. با وجود سختی ، ویژگی های شکل در برخی سیستم ها استفاده شده اند و مزایای بالقوه ای را برای RBIR نشان داده اند.
MPEG- 7 شامل ۳ توصیفگر شکل برای بازیابی تصویر مبتنی بر شئ است یکی توصیفگر شکل ۳-D است که از شبکه های ۳-D سطح شکل گرفته شده است ، یکی برای شکل مبتنی بر ناحیه است که از گشتاورهای Zernik گرفته شده است و دیگری برای فرم دادن مبتنی بر شکل است که از فضای مقیاس انحنا (CSS) گرفته شده است.
موقعیت مکانی
علاوه بر رنگ و بافت ، موقعیت مکانی نیز برای رده بندی ناحیه مفید است . برا ی مثال ، “دریا” و “آسمان” باید رنگ و بافت مشابه داشته باشند اما موقعیت های مکانی آنها متفاوت است آسمان معمولاً در بالای تصویر دیده می شود در حالی که دریا در پایین .
موقعیت مکانی به صورت بالا تر(فوقانی)، پایین و بالا مطابق با موقعیت ناحیه در یک تصویر تعریف می شود.
در برخی مطالعات انجام شده مرکز ثقل ناحیه و حداقل مستطیل مرزی آن برای ارائه ی اطلاعات موقعیت مکانی استفاده می شود و در برخی مکان مرکز یک ناحیه برای نشان دادن موقعیت مکانی آن به کار می رود .روابط مکانی نسبی مهمتر از موقعیت فضایی مطلق در استنتاج ویژگی های معنایی است .
کاهش شکاف معنایی
تکنیک های پیشرفته و بروز در کاهش شکاف معنایی می توانند به روش های متفاوت و از نقطه نظرهای متفاوت دسته بندی شوند . یکی از روش های کاهش شکاف معنایی، شئ – هستی شناسی است.
شئ – هست شناسی
در برخی موارد ، معانی می توانند به راحتی از زبان روزانه ی ما گرفته شوند . برای مثال ، آسمان می تواند به صورت ناحیه بالا، یکنواخت و آبی توصیف شود. در سیستم ها با استفاده از چنین معانی ساده ای ، اولاً فواصل متفاوتی برای ویژگی های سطح پایین تعریف می شوند که هر فاصله متناظر با یک توصیفگر تصویر سطح واسط(میانی) است ، برای مثال ، ‘light green, medium green, dark green’ . این توصیفگر ها یک واژگان ساده را شکل می دهند ، اصطلاح object-ontology که یک تعریف کیفی از مفاهیم سطح بالا ارائه می دهد. تصاویر پایگاه داده می توانند با نگاشت چنین توصیفگرهایی به معانی سطح بالا (کلمات کلیدی) بر مبنای دانش ما در گروه های متفاوتی دسته بندی شوند ، برای مثال آسمان می تواند به صورت ناحیه ای از آبی روشن (رنگ) ، یکنواخت (بافت) ، و بالا تر (موقعیت فضایی) تعریف شود. هستی شناسی شی در شکل ۳ نشان داده شده است. در این شکل هر یک از توصیفگرها ی سطح – میانی به یک رنج مناسب از مقادیر متناظر سطح پایین نگاشت شده اند.
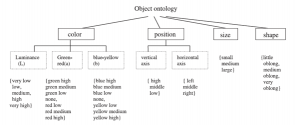
شکل ۳-۱٫ هستی شناسی شی
برای پشتیبانی بازیابی تصویر مبتنی بر معنا ، یک راه کارا و پر استفاده ارزیابی کردن اطلاعات رنگ با نام گذاری رنگ است. مدل های نام گذاری رنگ قصد دارند یک فضای رنگی عددی را با نام های رنگی معنایی استفاد شده در زبان طبیعی ارتباط دهند . معروف ترین سیستم نامگذاری رنگ CNS است که توسط Berk ، Brownston و Kaufman پیشنهاد شده است . CNSفضای HSL را به ۶۲۷ رنگ متمایز quantizes می کند. مشابه CNS یک نیاز موازی برای یک سیستم نامگذاری بافت وجود دارد که توصیف و ارائه ی بافت ها را استانداردسازی می کند. اما نامگذاری بافت بسیار دشوار است و تاکنون هیچ سیستم نامگذاری بافتی وجود ندارد .
در گام اول به سمت ایجاد یک سیستم نامگذاری بافت ، برخی پژوهشگران سعی کردند که مهمترین ویژگی هایی که انسان ها در ادراک (احساس) استفاده می کنند شناسایی کنند.
۲-۶-۱-بازخورد مرتبط RF
در مقایسه با الگوریتم های پردازشی افلاین ، rf یک پردازش انلاین است که برای یادگیری مقصود کاربران تلاش می کند. Rf یک ابزار قوی است که به طور سنتی در سیستم های بازیابی اطلاعات مبتنی بر متن استفاده می شود. در اواسط ۱۹۹۰ به CBIR معرفی کرد با نیت قرار دادن کاربر در چرخه ی بازیابی برای کاهش حفره ی معنایی بین چیزی که پرسوجوها ارائه می دهند (ویژگی های سطح پایین) و آنچه که کاربر فکر می کند.
یک سناریو نمونه برای rf در CBIR به صورت زیر است :
(۱) سیستم نتایج بازیابی اولیه را بر طبق query-by-example ، sketch و غیره ارائه می دهد
(۲) کاربر نتایج ارائه شده را بررسی می کند که نتایج تا چه حد مربوط (نتایج مثبت) یا نامربط(نتایج منفی) بوده اند
(۳) الگوریتم یادگیری ماشین برای یادگیری بازخورد کاربر اعمال می شود. سپس بازگشت به (۲) .
(۲)-(۳) تا زمانیکه کاربر از نتایج راضی شود تکرار می شوند . شکل ۴ یک نمودار ساده از یک سیستم CBIR با rf را نشان می دهد .
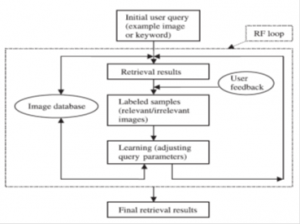
شکل۴-۱- بازیابی مبتنی بر محتوا با بازخورد مرتبط
مروری بر کارهای گذشته
۲-۱- روش SIMPLIcity:Semantics-Sensitive Integrated Matching for Picture Libraries
در این روش یک سیستم بازیابی تصویر که از روش های دسته بندی معنایی و استخراج خصوصیت بر پایه دیدگاه تبدیل موجک و تطابق ناحیه های ترکیب شده بر روی قطعه بندی تصویراستفاده می کند. از آنجایی که در بسیاری از سیستم های بازیابی تصویر یک عکس به وسیله مجموعه ای از ناحیه ها، مطابق با موضوعات ، که به وسیله رنگ ، بافت ، شکل و مکان مشخص شده اند . ارائه می شود .این سیستم تصاویر را در داخل دسته بندی های معنایی دسته بندی می کند که عبارتند از :
- بافت یا غیر بافت
- عکس یا غیر عکس
یک معیار برای شباهت سراسری بین تصاویر، تطابق خصوصیات ترکیب شده همه نواحی در تصویر است. دیدگاه سراسری شباهت در این روش به صورت زیر است:
۱- کاهش ناسازگاری قطعه بندی نادرست
۲- کمک به واضح تر کردن معنای ناحیه مخصوص
۳- اجرای query های ساده برای سیستم های بازیابی تصویر بر پایه ناحیه می باشد.
در طی ایندکس تصویر سیستم عکس را به بلاک های ۴*۴ پیکسلی پارتیشن می کند و برای هر بلاک یک خصوصیت را استخراج می کند. در ادامه از یک الگوریتم خوشه بندی آماری برای قطعه بندی سریع تصویر به ناحیه ها استفاده می شود. نتایج قطعه بندی به کلاس بند داده می شود تا در مورد نوع معنایی تصویر تصمیم گیری کند. یک تصویر در یکی از n دسته ای که به صورت دستی مشخص شده ، منحصر به فرد ، جامع و به صورت کلاس معنایی است ، قرار می گیرد. برای هر ناحیه در عکس خصوصیات منعکس کننده رنگ ، بافت ، شکل ، مکان ، استخراج یافته اند. خصوصیات انتخاب شده برای ناحیه ها بستگی به نوع معنایی تصویر دارد. خصوصیات کلی تصویر از مجموع خصوصیات ناحیه ها با معانی متفاوت به دست می آید. سپس خصوصیات تصاویر با معانی متفاوت در پایگاه داده های جدا ذخیره می شوند. در فرایند query، اگر تصویر داده شده توسط کاربر در پایگاه داده ای که به وسیله رابط کاربر نمایش داده می شود، نباشد، باید در ابتدا از فرایند استخراج خصوصیات همسان عبور کند که طی ایندکس تصویر استفاده شده بود. برای یک تصویر در پایگاه داده نوع معنایی آن در ابتدا چک می شود و سپس خصوصیاتش از پایگاه داده مربوط استخراج می شود. هنگامی که خصوصیت تصویر query به دست می آید، امتیاز همانندی بین تصویر query و تصاویر در پایگاه داده با نوع های معنایی همسان محاسبه می شود و بعد بر اساس امتیاز عکس ها مرتب می شوند.
۲-۱-۱- روش قطعه بندی تصویر
در اینجا الزامی برای قطعه بندی کاملا صحیح وجود ندارد، برای این که در مراحل بعد از IRM استفاده می شود تا بر قطعه بندی نامناسب غلبه شود. برای قطعه بندی تصویر ، در این مقاله ، تصویر را به بلوک های ۴ پیکسلی پارتیشن می کند و برای هر بلوک یک بردار خصوصیت را استخراج می کند. الگوریتم k-mean برای دسته بندی بردار خصوصیت در داخل چندین دسته که هر دسته مطابق با یک ناحیه در تصویر قطعه بندی شده است استفاده می شود . در شکل ۱-۲ یک نمونه قطعه بندی تصویر نشان داده شده است.

شکل ۱-۲ :قطعه بندی تصویر به ناحیه ها
در این مقاله از قطعه بندی blockwise به جای pixelwise ، به منظور کاهش حجم محاسبات استفاده شده است . به این صورت که تصویر به بلوک های بسیار کوچک تقسیم بندی می شود و یک رنگ کاندید از هر بلاک ، رنگ کل آن بلاک محسوب می شود و در ادامه هر بلاک در تصویر اصلی به عنوان یک پیکسل در تصویر جدید استفاده می شود.
هدف الگوریتم k-mean دسته بندی خصوصیات در داخل k گروه x ̂۱ , x ̂۲ ,…, x ̂K توسط این فرمول می باشد:
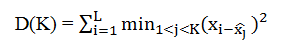
الگوریتم k-mean در ابتدا این که به چه تعداد دسته باید تقسیم شود را مشخص نمی کند.
تعداد این دسته ها که در آخر تعداد ناحیه های درون عکس خواهند شد به این صورت مشخص می شود که به طور تطبیقی تعداد دسته K را به وسیله افزایش k به صورت تدریجی انتخاب می شود و در صورتی که به معیار مورد نظر نزدیک شد کار را متوقف می کند.
ابتدا از k=2 شروع می شود و افزایش K را تا زمانی که به یکی از شرایط زیر برسد ادامه داده می شود:
- (D(k زیر حد تعیین شده باشد. یک D(k) کوچک رادر فرایند ناحیه بندی نشان می دهد.
- مقدار K از حد تعیین شده فراتر رود. حد بالایی برای ناحیه بندی در نظر گرفته شود مثلا تصویر از ۱۶ قطعه بیشتر نشود.
به ازای هر ناحیه ۶ خصوصیت برای قطعه بندی استفاده می شود.سه تا از این خصوصیتها میانگین رنگ اجزا در بلوک های ۴*۴ است و سه تای دیگر آن مربع ریشه دوم ضریب موجک در مرز فرکانس بالا می باشد .
در مورد سه تای اول از فضای رنگ LUV استفاده میکنیم که L روشنایی را نشان می دهد و U وV حاوی اطلاعات رنگ می باشند.LUV خصوصیت انطباق تصویر را به خوبی نمایش می دهد. به این نکته باید توجه شود که علت استفاده از بلوک های ۴*۴ این است که با خصوصیات بافت و زمان محاسبه هماهنگ باشد.
در مرحله اول اجرای تبدیل موجک بلوک های ۴*۴ به ۴ باند فرکانسی تجزیه می شوند.هر باند محتوی ضرایب ۲*۲ است که به وسیله فرمول زیر ، از آن ۳ خصوصیت استخراج می شود:
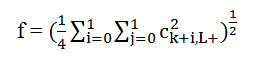
پانگیزه به دست آوردن این خصوصیات ، بازتاب خصوصیات بافت می باشد.به عنوان مثال نوار عمودی انرژی زیادی در باند HL و انرژی کمی در LH دارد.
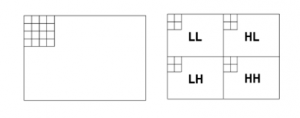
شکل ۲-۲: اعمال تبدیل موجک که در آن تصویر به ۴ باند فرکانسی تجزیه شده است
۲-۱-۲- روش های دسته بندی تصویر
در این روش عکس ها به صورت معنایی دسته بندی می شوند به عنوان مثال : داخل ساختمان یا خارج ساختمان، تصویر بافت دار یا بدون بافت ، تصویر با افراد یا بدون افراد.

شکل ۳-۲: چند تصاویر بافت
در ابتدا ما تصویر را به ۱۶ بخش تقسیم می کنیم به این صورت : {z_1,z_2 ,…, z_16}
فرض می کنیم تصویر به تعدادی ناحیه r_i قطعه بندی شده است i=1,2,…,m
بعد شاخص آمار x^2 برای ناحیه i به این صورت محاسبه می شود:
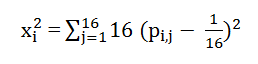
در ادامه برای این که بافت دار یا بدون بافت آن مشخص شود از آستانه میانگین (x^(-2 برای همه نواحی در تصویر استفاده می کنیم:
اگر x^(-2)< 0.32 باشد تصویر با عنوان تصویر بافت دار برچسب می خورد در غیر این صورت تصویر بدون بافت خواهد بود.
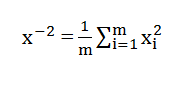
۲-۱-۳- معیار شباهت IRM :
IRM شباهت را در بین تصاویر به وسیله ترکیب خصوصیات همه ناحیه ها در تصاویر اندازه گیری می کند.در روشهای دیگر بازیابی تصویر به علت فقدان IRM ،قطعه بندی یا ناحیه بندی تصویر یک قسمت بحرانی محسوب می شود (شکل۴-۲) اما همانطور که در شکل ۵-۲ مشاهده می شود در روش به کار رفته دراین مقاله بحرانی نیست.
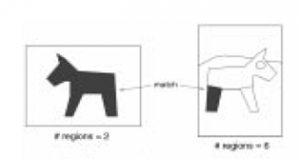
شکل ۴-۲: به علت قطعه بندی نادرست در تصویر اول قسمتی از موضوع یک ناحیه در نظر گرفته شده است و در تصویر دیگر که عکس سگ را درست قطعه بندی کرده تطابق هیچ سودی ندارد
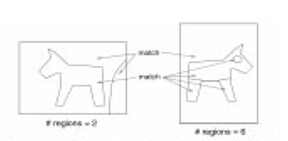
شکل ۵-۲ : در روش IRM یک ناحیه با چند ناحیه مقایسه می شود
به طور ریاضی ، تعریف اندازه همانندی برابر است با تعریف فاصله بین مجموعه ای از نقاط در فضای چند بعدی . هر نقطه در فضا برابر با بردار خصوصیت است یا توصیف کننده یک ناحیه محسوب می شود. اگر چه حساب کردن فاصله بین دو نقطه از طریق فاصله اقلیدسی راحت است اما روشن نیست فاصله بین دو مجموعه از نقاط خصوصیت را چگونه تعیین شود.
۲-۲- روش A Region-Based Fuzzy Feature Matching Approach to content-Based Image Retrieval
در این روش برای انطباق یکپارچه تصاویر به نام UFM در یک سیستم بازیابی تصویر مبتنی بر محتوا ارائه شده است. برای رسیدن به این هدف ابتدا تصویر را بخشبندی کرده و که هر بخش را توسط یک خصیصه فازی که بیانگر خصوصیات رنگ و بافت و شکل است توصیف می شود. بنابراین یک تصویر با یک مجموعه از خصوصیات فازی که مربوط به نواحی تصویر است بیان می شود. خصوصیات فازی عملاً بیانگر تغییر تدریجی در بین نواحی(حاشیه های تار بین نواحی) است ، به بیان دیگر با خصایص فازی می توان این تغییر تدریجی که باعث عدم اطمینان در مشخص کردن مرز بین نواحی می شود را وارد الگوریتم کرد. برای شباهت دو تصویر نیز از همین خصایص فازی استفاده می شود، معیار شباهت نیز همان UFM measure است که تمام خصایص نواحی دو تصویر را به صورت یکجا با هم مقایسه می کند. این روش در مقایسه با روشهای مبتنی بر بخشهای مستقل تا حد زیادی تاثیر بخشبندی نامناسب را در کارایی الگوریتم کاهش داده است و همچنین درک بهتری از تصویر ارائه می کند.
به منظور افزایش قدرت یک سیستم بازیابی تصویر مبتنی بر محتوا در مقابل ابهامات موجود در بخشبندی ،که معمولا اغلب به دلیل بخشبندی غیر صحیح رخ می¬دهد، ما یک روش انطباق یکپارچه خصوصیات تصویر (UFM) ارائه کرده ایم. این روش بر پایه تئوری منطق فازی استوار است. قبل از روش ارائه شده توسط این مقاله روشهای فازی دیگری هم در بازیابی تصویر استفاده شده اند اما روش ما از دو جنبه با آنها متفاوت است. این روش یک روش فازی انطباق خصایص مبتنی بر ناحیه است. در روش ما ابهامات مربوط به بخشبندی به عنوان مرزهای تار بین نواحی در نظر گرفته می شود. در روش ما به جای بردار خصیصه، ما یک مجموعه خصایص چند بعدی به نام خصیصه فازی در فضای خصایص رنگ، شکل و بافت داریم. بنابراین هر تصویر با استفاده از یک مجموعه از خصایص فازی نمایش داده می¬شود. خواص فازی عموما تغییرات بین نواحی که تار یا مبهم هستند را نمایش می دهد. آن یک وزن ، به نام degree of membership ، به هر خصیصه ، در فضای بردار خصایص، اختصاص می دهد. بنابراین هر خصیصه معمولا به دو فضا اختصاص دارد که درجه اختصاص به هر کدام از آن نواحی با وزن آن مشخص می شود. در سیستم های گذشته یک خصیصه دقیقا به یک ناحیه متعلق بود.
در اینجا یک معیار مشابهت جدید (UFM measure) بر اساس عملگرهای مجموعه های فازی ارائه شده است. مقایسه دو تصویر در سه مرحله انجام می گردد: اول : هر خصیصه فازی تصویر پرس و جو با تمامی خصایص فازی تصویر هدف مقایسه می شود(به روش برنده مقدم است). دوم: هر خصیصه فازی تصویر هدف، با تمامی خصایص فازی تصویر پرس و جو، با روش قبل مقایسه می شود. سوم: نهایتا شباهت کل UFM با استفاده از وزنهای بدست آمده از دو مرحله قبل محاسبه می شود.
سنگ بنای اصلی روش UFM در واقع همان بخشهای تصویر و خصیصه فازی مربوط به هر بخش است. در روش ما ابتدا تصویر پرس و جو و تصویر هدف بخشبندی می شوند ، سپس به هر بخش یک مجموعه خصیصه چند بعدی اختصاص می یابد. به مجموعه تمامی خصایص روی تمامی بخشهای تصویر خصیصه (signature) تصویر می گویند.
۲-۲-۱- بخشبندی تصویر
در این سیستم بخشبندی تصویر مانند روش ذکر شده در Simplicity می باشد بدین صورت که برای بخش بندی ابتدا تصویر را به تعدادی بلاک با اندازه ثابت تقسیم می کنیم ، سپس یک بردار خصیصه برای هر بلاک استخراج می شود. تصاویر مورد بررسی ما با اندازه ۲۵۶*۳۸۴ یا ۳۸۴*۲۵۶ هستند و همچنین اندازه بلاکهای مورد استفاده ما نیز ۴*۴ است، بنابر این برای هر تصویر ۶۱۴۴ بردار خصیصه وجود دارد و هر بردار خصیصه شامل ۶ خصیصه است. سه تا از آنها بیانگر میانگین خصیصه رنگ در یک بلاک هستند و سه تای دیگر برای نمایش میزان انرژی در فرکانس بالا در wavelet transform هستند که این نیز از طریق محاسبه ریشه دوم ممان درجه دوم ضریب wavelet در فرکانس باند بالا است. سیستم رنگ مورد استفاده، سیستم LUV است که L برای روشنایی و UوV برای نمایش اطلاعات رنگ استفاده می شوند.

الگوریتم ۱٫بخشبندی تصاویر و استخراج خصایص فازی
در اینجا ما کل سیستم را به صورت مرحله ای و ساخت یافته تشریح می کنیم:
پیش پردازش تصاویر پایگاه داده: در این مرحله روی تمامی تصاویر موجود در پایگاه الگوریتم را بررسی می کنیم و برای هر ک، signature(مجموعه خصایص فازی را روی تمامی نواحی) آن را بدست می آوریم. تمامی تصاویر در دو گروه با بافت و بدون بافت تقسیم می¬شوند. این فرایند برای تمامی تصاویر بسیار زمان بر است اما خوشبختانه این بار فقط یک بار برای کل تصاویر انجام می-شود.
پیش پردازش تصویر پرس و جو: در اینجا دو سناریو مطرح است:
- تصویر پرس وجو داخل پایگاه باشد: در این صورت اطلاعات این تصویر مانند اطلاعات سایر تصاویر موجود در پایگاه تصاویر در دو دسته با بافت و یا بدون بافت تقسیم شده است. در این صورت می¬توان اطلاعات این تصویر را به سادگی از میان مخزن اطلاعات تصاویر بیرون کشید.
- تصویر پرس وجو از تصاویر داخل پایگاه داده نباشد: در این صورت استدا تصاویر به فرمت استاندارد تصاویر پایگاه تصاویر در آوردن می شوند( برای مثال سایز آن هم اندازه تصاویر موجود در پایگاه می شود) سپس الگوریتم استخراج خصایص روی آن اعمال می¬شود تا بتوان خصایصی مشابه آنچه که در مخزن اطلاعات داریم بدست آوریم و سپس این اطلاعات را با هم مقایسه کنیم.
۳-۱- روش پیاده سازی شده :CLUE: Cluster-Based Retrieval of Images by Unsupervised Learning
اهداف سیستم های بازیابی تصویر مبتنی بر محتوا این است که تکنیک هایی را که از جستجوی کارا و جستجو از یک لیست از کتابخانه های دیجیتالی تصاویر بزرگ بر مبنای ویژگی های تصویری به صوت اتوماتیک استخراج شده پشتیبانی کنند، را توسعه دهند. مطالعات در این زمینه به سرعت روی سه فیلد پایگاه داده، بینایی ماشین، بازیابی اطلاعات گسترش یافت. اگرچه CBIR ها هنوز به رشد کامل نرسیدهاند،کارهای زیادی از قبل وجود دارد. به علت محدودیت فضا ما فقط کارهایی را مورد بازبینی قرار میدهیم که بیشترین ارتباط را با ما دارند.
همه تکنیک های CBIR جاری اطلاعات انحصاری ویژه ای را میان معیار های شباهت و معنای تصاویر فرض میکنند .یک نمونه سیستم CBIR تصاویر پایگاه داده را بر طبق شباهت هایی به نسبت تقاضا رتبه بندی میکند و شباهت میان تصاویر پایگاه داده را در نظر نمیگیرد.آیا ما میتوانیم کارایی یک سیستم CBIR را با افزودن اطلاعات شباهتی میان تصاویر پایگاه داده بهبود دهیم؟ این سوالی است که ما سعی داریم در این کار به دنبال پاسخی برای آن باشیم. ما یک تکنیک جدیدی برای بهبود تعامل کاربر با سیستم های بازیابی تصویر را بوسیله استخراج تمامی اطلاعات شباهتی پیشنهاد میکنیم. تکنیکCLUE خوشه های تصاویر را به جای یک مجموعه از تصاویر مرتب شده بازیابی میکند. تصویر درخواستی و تصاویر نزدیک در پایگاه داده که بر طبق معیار مشابهت انتخاب میشوند، بوسیله متد آموزش بدون ناظر خوشه بندی میشوند و به کاربر برگشت داده میشوند. از این طریق رابطه میان تصاویر بازیابی شده به تصویر کشیده می¬شود و این امکان برای کاربر فراهم می شود که سرنخهایی برای جستجوی تصویر مد نظر داشته باشد.
پیاده سازی روش CLUE دارای مشخصه های زیر است: آن یک متد مبتنی بر شباهت است که می تواند به طور مجازی روی هر معیار شباهتی پیاده سازی شود.
در نتیجه روش ما می تواند با بسیاری از شماهای بازیابی تصویر دیگر شامل روش RF به همراه بروز رسانی اتوماتیک مدل های معیار شباهت ترکیب میشود. بعلاوه در بخشهای بعد نشان داده خواهد شد که ممکن است از
-آن به عنوان بخشی از واسط سیستم های بازیابی تصویر مبتنی بر کلمه کلیدی استفاده شود.
آن از یک الگوریتم بر مبنای تئوری گراف به منظور تولید خوشه ها استفاده میکند. به طور ویژه یک مجموعه از تصاویر به صورت یک گراف بدون جهت وزن دار نمایش داده شده اند: گره ها بر تصاویر منطبق هستند و یال ها دو گره را به هم متصل میکنند و وزن روی یک یال با شباهت میان دو گره(یا دو تصویر) ارتباط دارد. نمایش مبتنی بر گراف و خوشه بندی محدودیتهای فضای متریک را کاهش می دهد. این امر برای معیارهای شباهت تصاویر غیرمتریک ضروری است( بسیاری از معیارهای شباهت غیر متریک هستند).
– خوشه بندی محلی و پویا است .در این مورد پیاده سازی روش Clue مشابه متدscatter/gather که برای بازیابی اسناد و متن پیشنهاد شده است، میباشد.خوشه های ایجاد شده به تصاویری در پاسخ به یک تقاضا بازیابی شده اند، وابسته هستند. در نتیجه خوشه ها این توانایی را دارند که با ویژگی های یک تصویر درخواستی به دقت منعطف شوند.
۳-۲- بازیابی شباهت القایی خوشه های تصاویر
در این بخش ما در ابتدا یک بازبینی روی سیستم های بازیابی تصویر خوشه ای ارائه میدهیم. سپس ما جزئیات مؤلفه های اصلی پیاده سازی روش CLUE بنام، انتخاب تصویر همسایه و خوشه بندی تصویر را توصیف میکنیم.
۱-۲- بازبینی سیستم
از نقطه نظر جریان داده، مشخصه های یک سیستم بازیابی تصویر خوشه ای را میتوان به صورت دیاگرام شکل ۱-۳ بیان کرد.
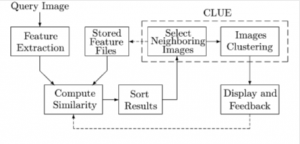
شکل ۱-۳ – فلوچارت Clue
پروسه بازیابی با استخراج ویژگی ها برای یک تصویر مورد پرس و جو شروع میشود. ویژگی ها برای تصاویر پایگاه داده معمولاً از قبل محاسبه شده و به عنوان یک فایل از ویژگی ها، ذخیره شده اند. با استفاده از این ویژگی ها به همراه معیار شباهت تصویر،شباهت های میان تصویر پرس و جو و تصاویر پایگاه داده ارزیابی شده و بر حسب شباهت مرتب میشوند. در ادامه یک مجموعه از تصاویر پایگاه داده که نزدیک به تصویر پرس و جو هستند به عنوان مشابه ترین تصویر انتخاب میشوند. سپس یک الگوریتم خوشه بندی روی تصاویر پایگاه داده اعمال میشود. در نهایت سیستم خوشه های تصاویر را نمایش میدهد و مدل معیار شباهت را منطبق با بازخورد کاربر وفق میدهد.(اگر شامل RF باشد). مهمترین تفاوت میان یک سیستم بازیابی تصویر خوشه ای و سیستم CBIR روی ۲ مرحله است که عبارتند از:
۱-انتخاب نزدیک ترین تصویر در پایگاه داده و خوشه بندی تصویر که جزء مؤلفه های اصلی پیاده سازی روش Clue هستند. یک نمونه سیستم CBIR با گذشتن از این دو مرحله ، مستقیماً خروجی ها را مرتب کند برای نمایش مرحله بازخورد. شکل ۱ پیشنهاد می کند کهCLUE می تواند جدا از مؤلفه هایش طراحی شود؛ زیرا تنها اطلاعاتی که CLUE به آن نیاز دارد شباهتهای مرتب شده است. اینکه CLUE میتواند در یک سیستم CBIR تعبیه شود از ویژگی های تصویریای که استفاده میشود، متد های مرتب سازی و اینکه آیا بازخورد وجود دارد یا خیر مستقل است. تنها نیازمندی یک معیار شباهت قانع کننده با مقدار حقیقی برای مشابهت ویژگیها است. در نتیجه، در زیر بخش های بعدی ما روی متدلوژی های عمومی پیاده سازی روش Clue با فرض یک معیار مشابهت معلوم تاکید خواهیم کرد. یک مقدمه ای از سیستم بازیابی تصویر خوشه ای ویژه که ما تکمیلش کردیم در بخش ۴ بیان خواهیم کرد.
۲-انتخاب نزدیک ترین تصاویر پایگاه داده بنا به قانون ریاضی ما برای تعریف همسایگی یک نقطه نیاز به یک معیار فاصله داریم. برای تصاویر فاصله میتواند هم بوسیله یک معیار مشابهت(مقادیر بزرگ نشان دهنده فاصله کم) و یا عدم مشابهت(مقادیر کوچک نشان دهنده فاصله کوچک) تعریف شود.
زیرا عملگر های ساده جبری میتوانند معیار مشابهت را به معیار عدم مشابهت تبدیل کنند، بدون از دست دادن کلیات،ما فرض می کنیم که فاصله میان دو تصویر بوسیله معیار عدم مشابهت متقارن![]() تعیین میشود و نام (d(i,j فاصله میان فاصله میان تصویر i,j است. در ادامه ما دو متد ساده را پیشنهاد میکنیم به منظور انتخاب کردن یک مجموعه از همسایه های تصاویر پایگاه داده با تصویر در خواستی
تعیین میشود و نام (d(i,j فاصله میان فاصله میان تصویر i,j است. در ادامه ما دو متد ساده را پیشنهاد میکنیم به منظور انتخاب کردن یک مجموعه از همسایه های تصاویر پایگاه داده با تصویر در خواستی
۱) متد شعاع ثابت (FRM) که تمامی تصاویر پایگاه داده را با شعاع ثابت e نسبت به i در نظر میگیرد.برای یک تصویر درخواستی معلوم تعداد همسایه ها در پایگاه داده تصاویر بوسیله e تعیین میشود.
۲) متد نزدیک ترین همسایه (NNM ) در ابتدا K تا نزدیکترین همسایه به I را انتخاب میکند .R تا نزدیکترین همسایه برای هریک سپس پیدا میشود. سپس همسایگی تصاویر پایگاه داده با توجه به تمامی جوابهای بدست آمده برای هر یک از تصاویر ثقل به طور مجزا و نزدیکترین همسایه های آن ایجاد می شود.
بخش بندی گراف خیالی
تحت نمایش گراف، خوشه بندی میتواند برای مشکل بخش بندی گراف به طور طبیعی فرموله شود. در میان الگوریتم های تئوری گراف، متد پارتیشن بندی گراف خیالی با موفقیت در بسیاری از ناحیه ها در بینایی ماشین شامل تجزیه تحلیل حرکت، قطعه بندی تصویر و تشخیص اشیا به کار برده شد. در این مقاله ما از یکی از تکنیک ها متد برش نرمال (Ncut) برای خوشه بندی تصاویر استفاده میکنیم. در مقایسه با متد پارتیشن بندی گراف خیالی، مثلاً میانگین برش و میانگین وابستگی، متد Ncut از روی نمایش های تجربی نشان داد که در برابر تولید کلاستر های متوازن پایدار تر است. بعداً ما یک بازبینی از متد Ncut مبتنی بر کارهای Shi and Malik’s ارائه میکنیم. گذشته از جزئیات یک متد پارتیشن بندی گراف سعی میکند تا گره ها را به گروه هایی بطوریکه شباهت داخل گروه بالا باشد و یا شباهت میان گروه ها کم باشد، سازمان دهی کند. یک گراف معلوم G=(V,E) با ماتریس همبستگی W یک روش ساده است برای تعیین کردن هزینه پارتیشن بندی گره ها را به دو مجموعه گسسته A,B است وزن نهایی یال هایی است که دو مجموعه را به هم متصل میکند در تئوری گراف این هزینه یک cut نامیده میشود.
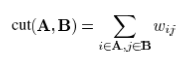
به طوریکه میتوان به عنوان معیاری از شباهت میان گروه ها در نظر گرفته شود.
پیدا کردن یک bipartition از گراف که این هزینه cut مینیمم کند به مشکل minimum cut معروف است. الگوریتم های کارامدی برای حل این مشکل وجود دارد.
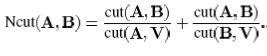
یک cut نامتوازن میتواند مقادیر Ncut بزرگی را تولید کند.
پیدا کردن تقسیم بندی با کمترین مقدار Ncut یک مسئله NP-complete است. Shi and Malik یک روش تقریبی برای این مسئله ارائه کرده اند.
![]()
متد Ncut را می توان به صورت تکراری انجام داد تا بتوان به تعداد کلاسترهای بیشتری دسترسی پیدا کرد، اما اینجا دو سوال مطرح می شود. ۱- کدام زیر گراف باید تقسیم شود؟ ۲- این روند تا کی باید ادامه پیدا کند. در این مقاله ما یک روش ابتکاری را برای انتخاب زیر گراف انتخاب کردهایم، در این روش ما زیر گراف بزرگتر را برای تقسیم انتخاب می کنیم و این فرایند تا رسیدن مقدار Ncut به یک حد آستانه ادامه می یابد.
۲-۵- یافتن یک نمونه تصویر برای یک گروه
سر انجام سیستم نیاز دارد که تصاویر خوشهای پایگاه داده را به کاربر نشان دهد. علیرغم یک سیستم CBIR ،که تعداد مشخصی از مشابه ترین تصاویر را به کاربر نشان میدهد، یک سیستم بازیابی تصویر خوشهای باید قادر باشد تا یک درک شهودی از ساختار خوشه ای بعلاوه تمام تصاویر بازیابی شده از پایگاه داده فراهم کند. به این دلیل ما یک شمای نمایش دو سطحی پیشنهاد میکنیم. در سطح اول، سیستم یک مجموعه از تصاویر نماینده را برای هر خوشه (یک یا هر خوشه) نمایش میدهد. در سطح دوم سیستم همه تصاویر پایگاه داده ای در یک خوشه تعیین شده بوسیله یک کاربر را نمایش میدهد.
سیستم از همان شمای استخراج ویژگی و معیارهای مشابهت که در SIMPILICITY و UFM بیان شده است، استفاده میکند. تنها یک مقدمه مختصری در این جا مطرح می کنیم. از نقطه نظر ویژگی تصاویر، سیستم یک سیستم مبتنی بر ناحیه است. آن در قطعه بندی تصاویر به منظور تجزیه کردن یک تصویر به نواحی بکار میرود و شباهت ها را با تطبیق نواحی تعیین میکند. برای قطعه بندی یک تصویر ،سیستم ما در ابتدا یک تصویر را به بلاک هایی از ۴*۴ پیکسل تقسیم کرد .یک بردار ویژگی شامل ۶ ویژگی سپس برای هر بلاک از تصویر استخراج شد. در میان ۶ ویژگی ،۳ تا از آنها میانگین رنگ بلاک های نظیر به نظیر (در فضای رنگی LUV) هستند. ۳ تای دیگر نمایش انرژی در محدوده فرکانس بالا را نشان می دهند.
سپس برای دسته بندی بردار های ویژگی به چندین کلاس به همراه مطابقت دادن هر کلاس به یک ناحیه از تصویر قطعه بندی شده الگوریتم میانه k استفاده می شود. هر ناحیه سپس به همراه یک ویژگی فازی (تعریف شده بوسیله membership function) توصیف کننده خواص رنگ و بافت و شکل از هر ناحیه اشتراک داده میشود. تابع عضویت از مجموعه های فازی ذاتاً مشخص میکند تحول تدریجی میان نواحی یک تصویر را.در نهایت مرزهای تار بین نواحی که به علت بخش بندی ناصحیح اتفاق افتاده است را می توان در الگوریتم وارد کرد.
یک معیار مشابهت فازی استفاده میشود برای توصیف کردن تشابه دو ناحیه استفاده می شود. سرانجام یک معیار شباهت فازی برای نشان داده میزان شباهت دو ناحیه از تصویر استفاه می شود.
سرانجام یک شمای ترکیبی محدب شباهت های سطح ناحیه به یک معیار شباهت تصویر تقریب می زند. معیار تطبیق ویژگی یکپارچه (ufm) که ثابت میکند روابط قطعه بندی خیلی پایدارند .به منظور محاسبه ماتریس مجاورت بر طبق رابطه ۱ معیار ufm تبدیل میشود به یک فاصله با استفاده از یک تبدیل ساده خطی تفاضل از UFM سیستم یک واسط کاربر ساده دارد که به کاربر یک مجموعه تصادفی از تصاویر پایگاه داده را در ابتدا میدهد.به علاوه کاربر میتواند id یک تصویر را به عنوان یک پرس و جو بوسیله وارد کردن url تصویر وارد کند زمانی که یک تصویر پرس وجو دریافت میشود سیستم یک لیست از نماینده های هر خوشه تصویر را نشان می دهد.
۳-۳- نتایج
در شکل زیر رابط گرافیکی تهیه شده برای بازیابی تصاویر به روش Clue آورده شده است. همانطور که در شکل مشاهده می کنید خروجی تصاویر، به صورت لیستی ارائه می شود که از پوشه تصویر Query استخراج می شود.
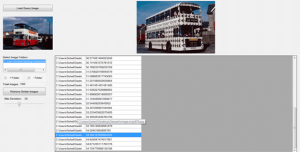
Dataset مورد استفاده در این پروژه ، مجموعه ۱۰۰۰۰ تایی از تصاویر مختلف است که توسط Jia Li, James Z. Wang برای بررسی پروژه نرم افزار Simplicity مورد بررسی قرار گرفته است.
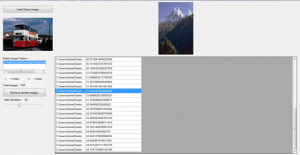
در نهایت امر با توجه به این که از بازخورد مرتبط یا RF استفاده نشده است، توانستیم به مقدار ۶۳% درستی در بازیابی تصاویر این مجموعه داده ای دست پیدا کنیم .
نتیجه گیری
در این گزارش پیاده سازی روش Clue را به عنوان یک شمای جدید بازیابی تصویر برای بهبود تعامل کاربر با سیستم بازیابی تصویر معرفی کردیم. پیاده سازی روش Clue خوشه های تصاویر را سریعتر از تک تصویر جور شده که در بیشتر سیستم های بازیابی تصویر انجام میشود؛ بازیابی میکند. خوشه بندی با یک روش وابسته به پرس و جو صورت میگیرد.بنابراین CLUE کلاسترهایی را تولید میکند که مناسب هستند برای مشخصات تصاویر پایگاه داده. خوشه بندی طبیعتاً به صورت مشکل پارتیشن بندی گراف در می آید که برای حل این مشکل از تکنیک Ncut استفاده میشود.خوشه بندی تئوری گراف ها CLUE را قادر میسازد که معیار های شباهت متریک و غیر متریک را از طریق یک روش یکسان دستکاری کند. در این مورد CLUE یک روش عمومی است که میتواند ترکیب شده با هر معیار مشابهت تصاویر متقارن با مقادیر حقیقی و بنابراین میتواند در سیستم های CBIR تعبیه شود.نتایج تصاویر باز گردانده شده پیشنهاد کرد پتانسیل Clue را برای تصاویر دنیای واقعی و پیاده سازی روش Clue را به عنوان بخشی از واسط سیستم بازیابی تصویر مبتنی بر کلمه کلیدی کامل کرد.
دانشگاه آزاد اسلامی واحد تهران شمال
گردآورنده: دکتر سهیل تهرانی پور ” دانشجوی دکترای هوش مصنوعی “