


در این ویدیو، ایمان دهقان (دانشجوی دکتری هوش مصنوعی و رباتیکز) به بررسی نحوه حل مساله آونگ وارونه یا Cart Pole Balancnig با یادگیری تقویتی یا Reinforcement Learning می پردازد. کنترل آونگ وارونه یکی از مسائل کلاسیک و مورد توجه در کنترل سیستم ها است که تاکنون روش های مختلفی برای کنترل آن پیشنهاد شده است . آونگ وارونه مسأله ای کلاسیک است و به طور گسترده به عنوان معیاری برای تست الگوریتم های کنترل به کار می رود. مشکل اصلی، کنترل آنلاین این سیستم تحت شرایط متغیر محیطی و امکان تطبیق پذیری هر چه بهتر این سیستم با محیط است.
سیستم پاندول معکوس از یک آونگ متصل به یک ارابه (Cart) تشکیل شده است، به طوری که ارابه با نیروی اعمال شونده به سمت چپ و راست حرکت می کند. هدف قراردادن آونگ در وضعیت قائم رو به بالا و حفظ آن در همان موقعیت می باشد، ضمن اینکه ارابه نیز باید حتی الامکان در مرکز خط ریل قرار گیرد و به گوشه ها برخورد نکند.
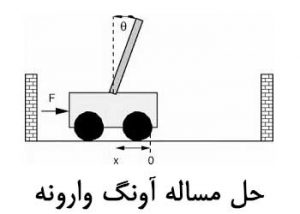
در مساله پاندول معکوس یا آونگ وارونه، شکست (Failure) بدین صورت تعریف می شود:
اگر زاویه آونگ از یک حدی تجاوز کرده یا ارابه از محدوده تعریف شده خارج شود (به اطراف برخورد کند). دراین صورت ارابه به صورت عمودی در می آید. به تعادل رساندن ارابه می تواند اپیزودیک (مرحله به مرحله) باشد و این اپیزودها تکرار می شوند تا پارامترهای مرتبط با actionبه درستی تعیین شده و ارابه به تعادل برسد.
پاداش در هر مرحله می تواند عدد +۱ به ازای هر مرحله ( )step تعیین شود تا زمانی که شکست اتفاق نیفتد. درنتیجه جمع پاداش در حقیقت تعداد مرحله ها (stepها) تا رخداد شکست تعریف می شود. به منظور توسعه یادگیری تقویتی می توان بعدها به صورت مداوم ( )continuing taskاز روش discountingنیز استفاده کرد. در این روش هربار رخداد شکست معادل با –۱ و سایر حالات معادل ۰ می باشد. در این حالت پارامتر return به صورت تعریف می شود که در آن K تعداد مرحله ها قبل از رخداد شکست می باشد. در هر دو روش به جهت عمود نگه داشته شدن آونگ برای بیشترین مدت زمان ممکن، مقدار پارامتر return بیشینه می شود.
شبیه سازی به زبان متلب این مساله را پیاده سازی کرده و از الگوریتم Sarsa استفاده کرده است و متعلق به Jose Antonio Martin آقای مارتین می باشد .
اصلی ترین متدی که شبیه سازی را اجرامی کند فایل Demo.m می باشد و توسط تایپ عبارت () Demo نیز شبیه سازی اجرا خواهد شد. پس از تعریف مقادیر اولیه متد اصلی این شبیه سازی با عنوان (Cart_PoleDemo(maxepisodes اجرا می شود و به عنوان پارامتر ورودی مقدار حداکثر تعداد مراحل قابل اجرا برای آن ارسال می شود . پارامترهای اولیه در این قسمت مقدار دهی می شوند.
دانلود گزارش و سورس کد (یادگیری تقویتی)
فایل گزارش این پروژه به همراه سورس کد از طریق لینک زیر در اختیار مخاطبان آکادمی یادگیری ماشین ایران قرار گرفته است.
دانلود گزارش پروژه Cart Pole Balancing توسط الگوریتم های یادگیری تقویتی (Reinforcement Learning)
دانلود سورس کد پروژه Cart Pole Balancing توسط الگوریتم های یادگیری تقویتی (Reinforcement Learning)





